Search
Search


MENU
みなさんは、「送られてきた電子メールが読めない」などの、コンピューター上で文字を正しく読めないという体験をしたことありませんか?今回は、コンピューターで文字が正しく読めなくなる現象(文字化け)が発生した時に、どうやって解決するかの代表的な例についてご紹介します。
その為には、まず文字をどのようにしてコンピューターで表示されているかを知る必要があるでしょう。
私達は普段から、コンピューターで文字を打ち込んだり表示したりしていますが、実はコンピューターでは文字を文字として扱うことができません。では、どうやって文字を表現しているのでしょう。
コンピューターの世界では、内部を流れる電流がある場合のON「1」と、ない場合のOFF「0」の二つの値しか扱えない為、文字を表現するためには「1」「0」の配列を文字に割り当てた表と照らし合わせて文字に変換して表示しています。「1」「0」で計算する方式を2進数(2進記数法)といい、2進数の一桁を1bitと表現します。
基本的には、半角英数字1文字を1バイト(=8bit)で表現し、日本語などの全角1文字は2バイト(=16bit)で表現します。
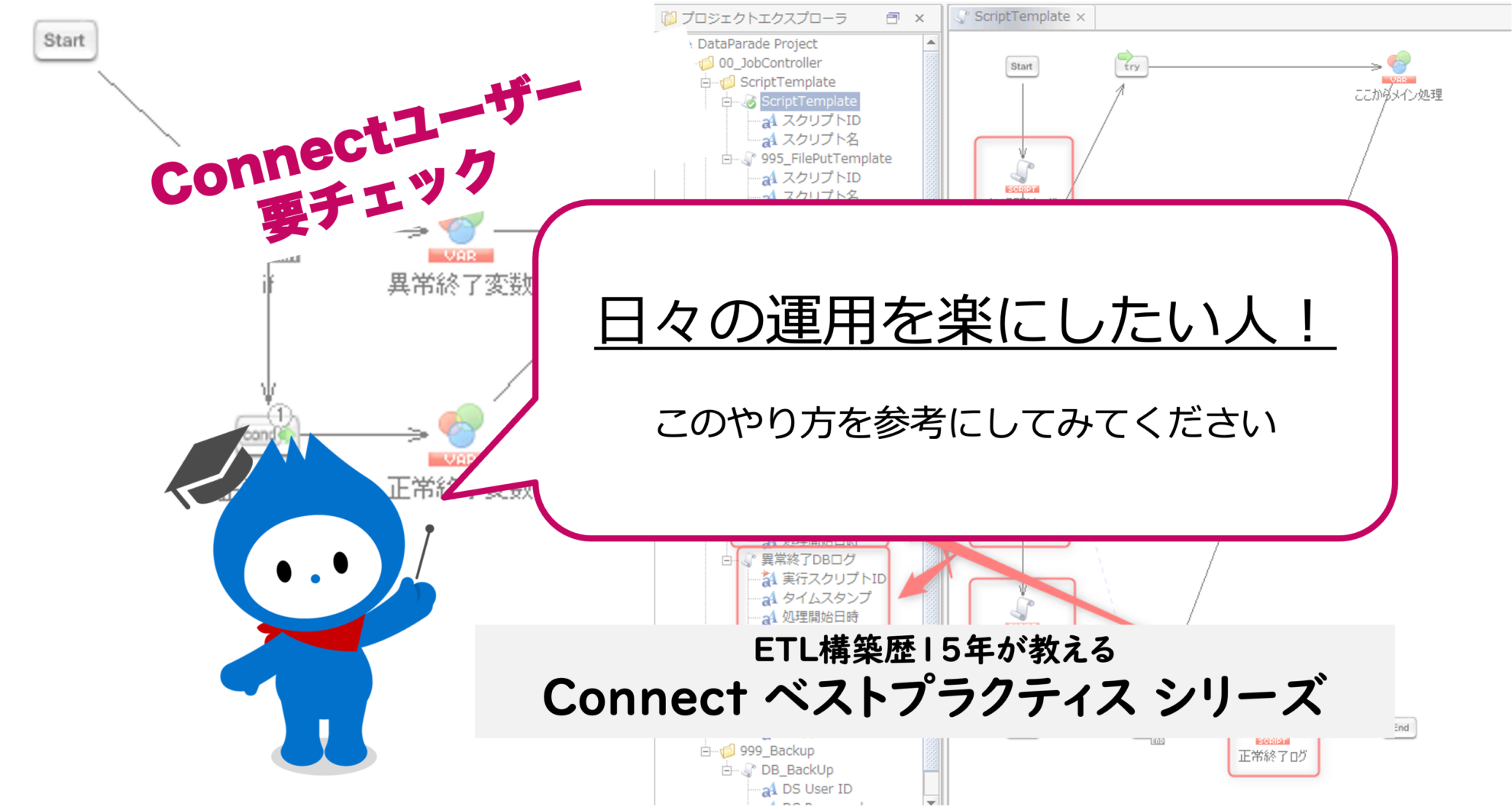
Windows10のShift_JISでの文字コード表の例は上図の通りです。例えば、「帳」の文字の文字コードは、Shift_JISでは16進数で「92A0(2バイト)」、これをコンピューター上で扱える「1」「0」で表示すると、「1001001010100000」になります。
文字コードの世界は非常に複雑ですので、ここでの文字コードの理解度は「そういう対応表があるんだね」レベルでダイジョウブです。
(人が使う文字も各国様々で、とても難しいですよね。それをコンピューターは「0」「1」の組み合わせのみで表現するんですって。。。。。。うーん複雑><)
そもそも、なんで文字化けはおきるのでしょうか?
原因は色々ありますが、代表的なものを挙げてみると
などが考えられます。
簡単にいえば、数値を文字に正しく変換できなかったということになります。
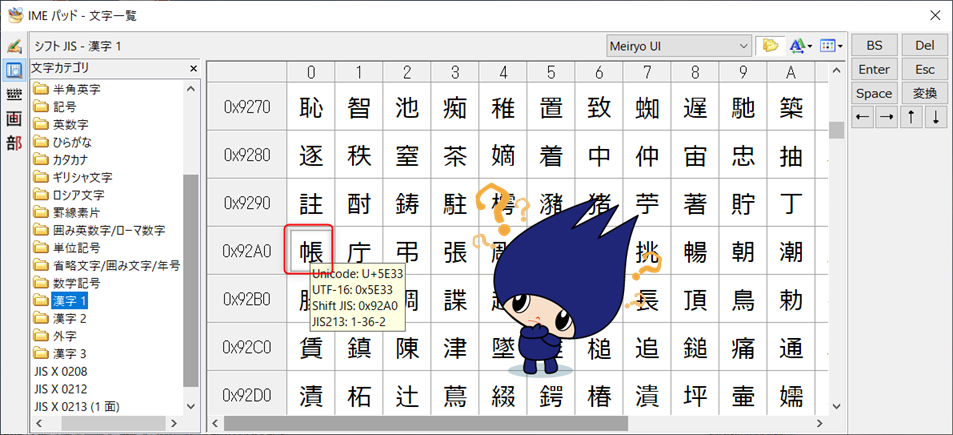
 エンコードを間違えると上図のように文字化けしてしまいます。(同じファイルを開いてもエンコードが違うと文字化けする)
エンコードを間違えると上図のように文字化けしてしまいます。(同じファイルを開いてもエンコードが違うと文字化けする)
一方、半角英数字などは文字化けしていませんよね。
アルファベット、数字(アラビア数字)、いくつかの基本的な記号などは機種などに依存しない基本文字として定義されているからです。
上図のような多機能なテキストエディターは、データを読み込む際のエンコードが指定できるものもあります。
ソフトやハード環境や言語などの違いでいろんな場所で文字化けは発生しますが、このブログは帳票のSVF(TIPS)ですので、SVFの帳票を出力する場合を例にして考えてみましょう。
SVFは、いろいろなエンコードの元データーを入力として、マルチプラットフォーム(WindowsやUnix、Linux)で動作し、多言語(ブログ掲載時、26か国語)で出力可能な製品です。
また、出力されたデータは、電子データではPDF等を出力し、印刷ではプリンターで印字します。電子データを表示する端末や印刷するプリンターが異なれば、出力される内容も異なります。
<SVFで文字化けした際のチェックポイントの例>
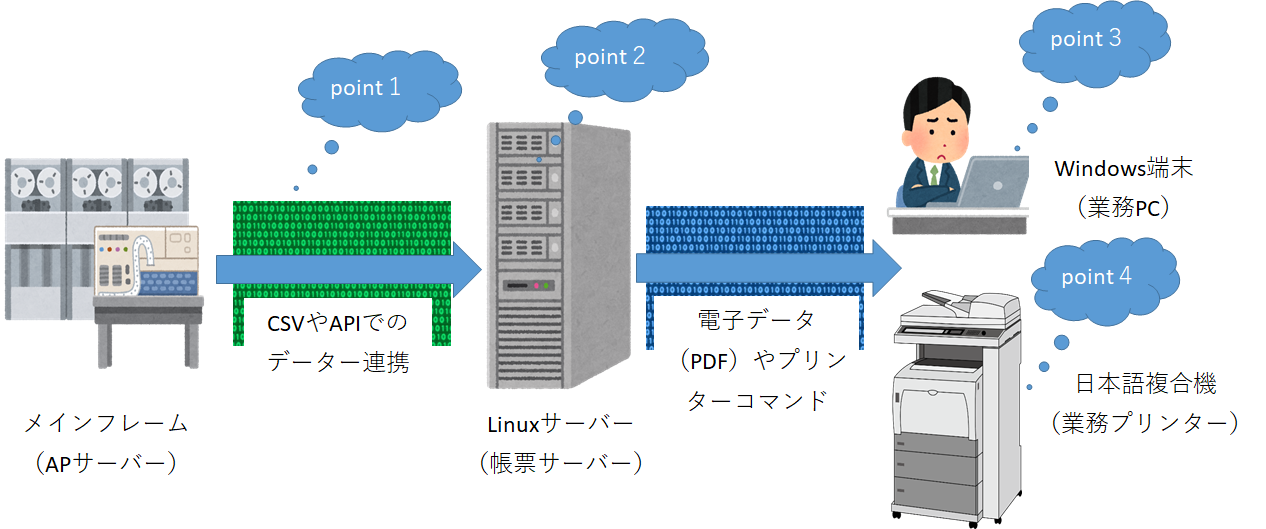
| Point1 | 渡すデータと受け取るデータで、エンコードが一致していること。 改行コードなどの特殊なコードが影響していないこと |
| Point2 | SVFの動作するエンコードは適切か? VrInit関数でエンコードを指定(SJISやMS932など)SVFのデバッグログを確認すると、正しい文字が表示されているか確認できます |
| Point3 | 端末が正しいエンコード表示できること。フォントが搭載されていること (英語版Windowsなどは日本語フォントが入っていない可能性があります |
| Point4 | プリンター記述言語が正しいこと。プリンターにフォントを搭載していること。プリンターの仕様書からプリンター記述言語(RPCS,LIPS4,PostScript,ART4,NPDL2,ESC/Pageなど)と、日本語フォントが搭載されているかを確認できます |
どこで文字化けしたかが確認できれば、確認するポイントを特定することが簡単になります。処理の最初から文字化けしている場合は、最後まで文字化けし続けるので、Point1から順番に文字化けがないかを確認するのが確実でしょう。
一般的に、文字化けは日本を含む東アジア圏「CJK統合漢字(中国語、日本語、朝鮮語)エリア」のようにアルファベットや数字・半角記号のような1バイトのみで表せない漢字や文字を表現する時などに、コードの組み合わせに合った文字が表現できない時に、文字化けが多く発生する傾向にあります。
(最近は、UTF-8などの文字コードが一般的になって来たので、スマホやPC、MAC間でも文字コードのトラブルはだいぶ減りましたね)
それらの問題に対応するため、SVFは文字に対する機能設定やノウハウで多くの課題を解決することが可能です。
(SVFのみでは解決できない場合もあります)
文字化けが発生した時は、
のように、入口から順番に確認してみるとわかりやすいかもしれません。
また、同じ帳票が出力するプリンターによって、文字化けするものとしないものがあるという話をよく聞きますが、この場合はプリンター周辺の環境に文字化けの要因があるはずです。
本記事が文字化けの原因究明と解決策に少しでも役立ててもらえればうれしく思います!
文字に関連する記事も過去に複数紹介していますので、参考にしてみてください。
Related article
Pick up
Ranking
Info