Search
Search


MENU
Dr.SumにはPythonとの連携機能があります!Dr.Sumに蓄積された大量のデータに対して形態素解析や回帰・分類など、より高度な分析を行うことができます!
形態素解析とは例えば「これはペンです。」といった文章を「これ」や「ペン」など、品詞ごとに分割する手法です。ワードクラウドと組み合わせると、SNSの投稿からトレンドワードを視覚的に表現したり、飲食店のレビューから頻繁に取り上げられるメニューをピックアップするといった分析が可能です。
今回はとあるレストランのコメントを例にPython連携機能で形態素解析を行い、MotionBoardのワードクラウドで可視化する方法を紹介します。

本記事では上記の形態素解析を行うための方法を最短距離で紹介していきます。そのため、Pythonの基本や本来必要なデバッグ作業、Python連携機能特有の記述については深く触れずに紹介していきます。興味のある方はマニュアルに一連の流れを体験できるチュートリアルもありますので、こちらをご覧ください!
※注意点※
Python連携機能の使用にはインメモリオプションが必要です。
オープンソースソフトウェア「MeCab」のインストールが必要です。セキュリティにご注意ください。
Dr.Sum バージョン 5.6.00.1030.23020316で動作することを確認しています。
本記事に必要なサンプルデータおよび、Pythonスクリプトはこちらからダウンロードください。
今回はとあるレストランのコメントデータをサンプルとして使います。「restaurant_comments」というテーブルにZIPファイル内にある「restaurant_comments.csv」をインポートします。例では「Python連携」というデータベースに格納しています。
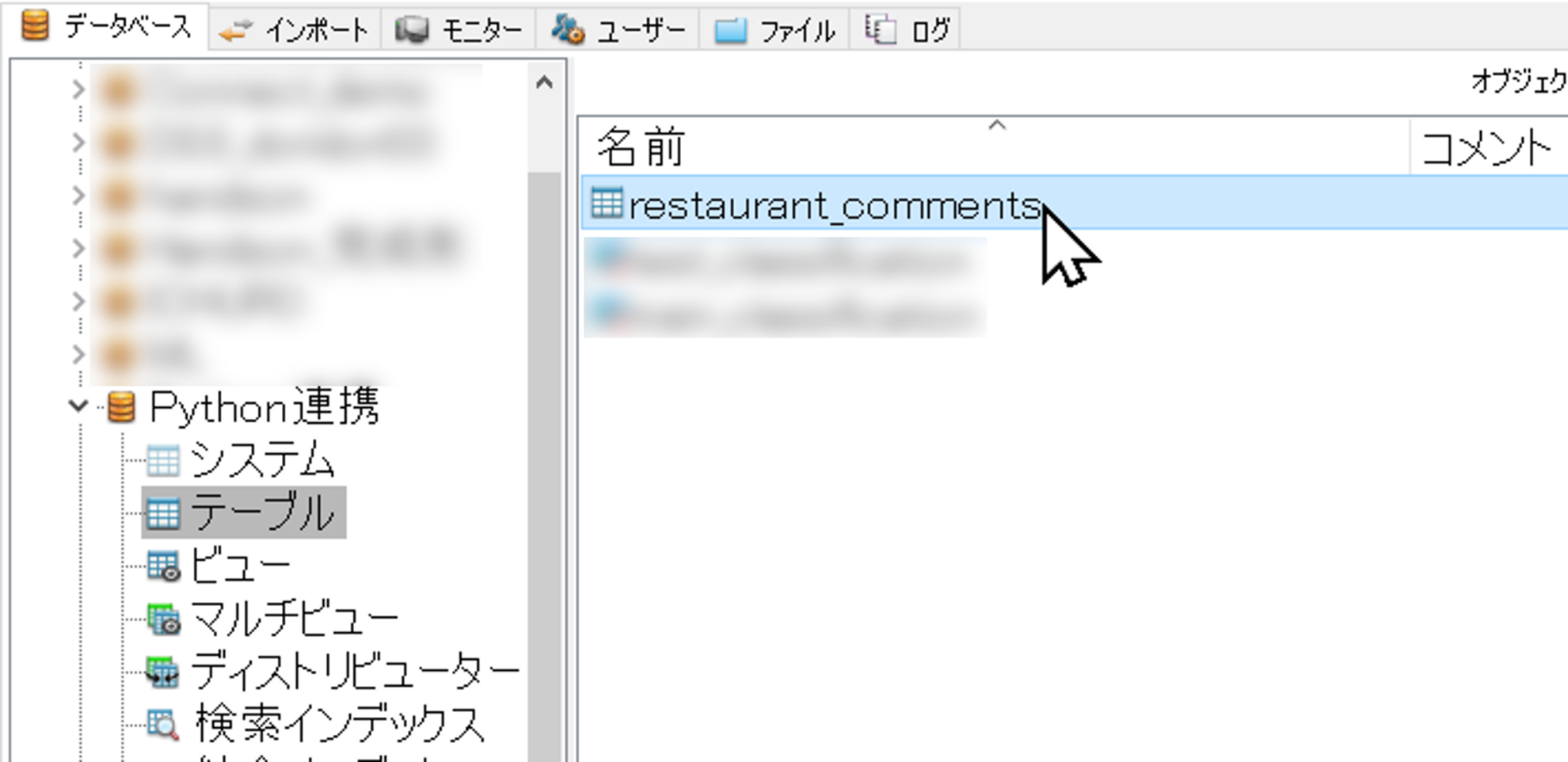
CSVの中身はこのようになっています。サンプルということで、一部文章が変ですがあしからず。。。
ID,年齢,性別,コメント
1,52,その他,感動的な魚料理が食べられて、完璧なサービスが最高の。リラックスできる雰囲気で、とても満足でした。次は友人と来たいです。- 田中
2,42,男性,最高のパスタが食べられて、迅速なサービスが豪華な。歓迎される雰囲気で、とても満足でした。また来たいです。- 山田
3,53,男性,最高のステーキが食べられて、素晴らしいサービスが豪華な。ロマンチックな雰囲気で、とても満足でした。また来たいです。- 木村
4,22,その他,最高のステーキが食べられて、フレンドリーなサービスが豪華な。ロマンチックな雰囲気で、とても満足でした。友人にもおすすめしたいです。- 鈴木
5,54,その他,素晴らしいパスタが食べられて、気配りのあるサービスが豪華な。居心地が良い雰囲気で、とても満足でした。次は友人と来たいです。- 佐藤
6,25,男性,美味しいスープが食べられて、迅速なサービスが美味しい。心地よい雰囲気で、とても満足でした。友人にもおすすめしたいです。- 田中
Pythonスクリプトはインメモリサーバー上で実行されます。そのため、インメモリサーバーの登録及び、対象テーブルのインメモリ化を行います。設定自体は難しくないのでご安心を!
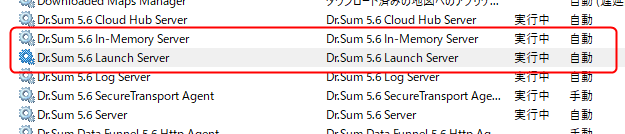
まずはサービスの起動を行います。Windowsのサービスを起動し、「Dr.Sum X.X In-Memory Server」及び「Dr.Sum X.X Launch Server」が起動していることを確認します。
インメモリサーバーの登録を行います。※ インストール時に登録した場合は飛ばしてOKです。
| インメモリサーバーをDr.Sum Serverに登録する |
登録後、利用するインメモリサーバーをEnterprise Managerから選択します。
| 使用するインメモリサーバーを選択する |
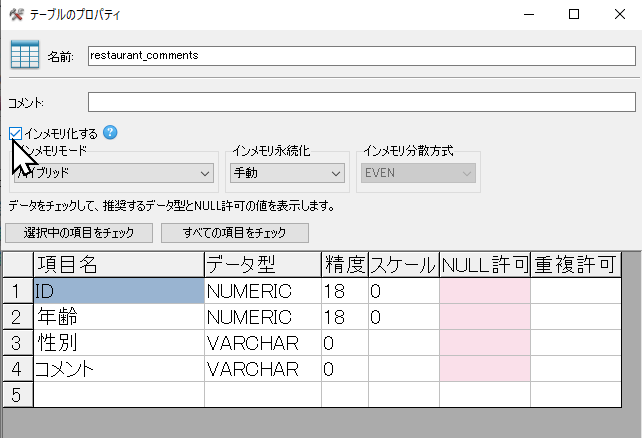
最後に、サンプルデータのテーブルをインメモリ化します。
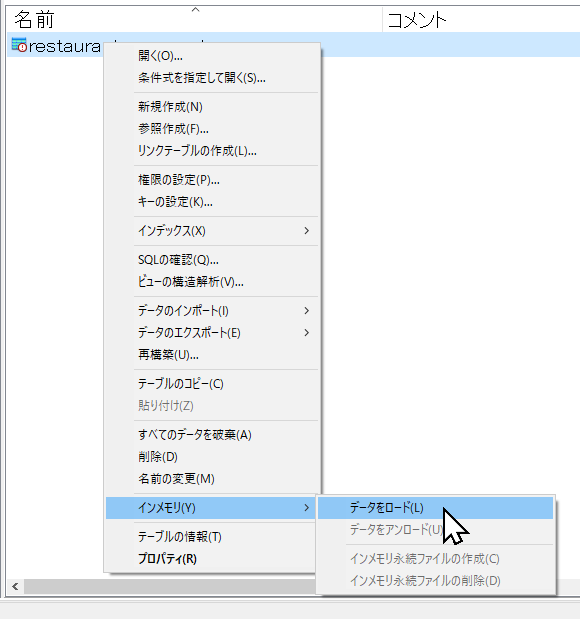
ZIPファイルの中にある「morph_analysis.py」を「<Dr.Sum のインストールフォルダ>\Server\samples\udtf-py\script\」直下に配置します。
スクリプトの中身はこのようになっています。
import MeCab
import pandas as pd
# 結果表スキーマ取得関数
def schema_func(input_schema):
# 形態素解析の結果を追加
return input_schema + ["品詞 VARCHAR", "単語 VARCHAR", "基本形 VARCHAR"]
# 処理関数
def proc_func(context, input, *args):
keitaisoStyle = "-Owakati" #"mecabrc" "-Ochasen" "-Owakati"
mecab = MeCab.Tagger(keitaisoStyle)
targetKey = args[0]
df_bf = pd.DataFrame(columns = input.columns)
addColumnName = ["品詞", "単語", "基本形"]
extWordClass = ["名詞", "動詞","形容詞"]
dropColumnName = []
df_bf = df_bf.drop(columns=dropColumnName)
for cname in addColumnName:
df_bf[cname] = ""
for recordIdx, requestSentence in enumerate(input[targetKey]):
mecab.parse('')
node = mecab.parseToNode(str(requestSentence))
# print(recordIdx, mecab.parse(requestSentence).split(" "))
while node:
if(node.surface==""):
node = node.next
continue
keitaisoList = node.feature.split(",")
# print(keitaisoList)
if(keitaisoList[0] in extWordClass):
# print(node.surface, keitaisoList)
tmp = [keitaisoList[0], node.surface, keitaisoList[6] if len(keitaisoList)>=8 else node.surface]
add_df = pd.DataFrame([input.iloc[recordIdx].to_list() + tmp], columns = df_bf.columns)
df_bf = pd.concat([df_bf, add_df], axis=0)
node = node.next
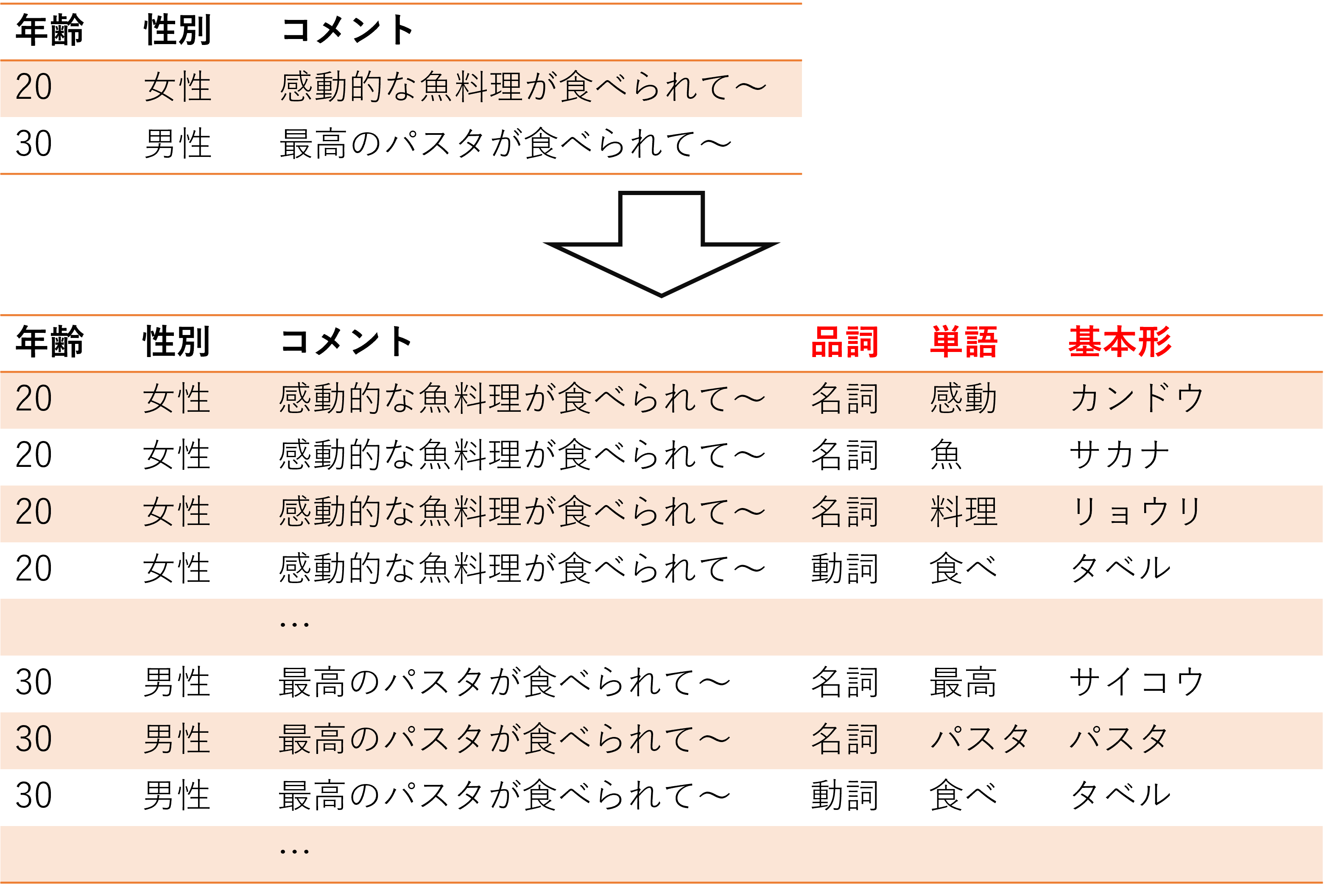
return df_bfスクリプトでは、以下の2つの処理を行っています。
出力するテーブルに品詞、単語、基本形の3項目を追加
MeCabのライブラリを使って形態素解析を行い、名詞、単語、形容詞のいずれかであれば出力テーブルに追加
今回は形態素解析でよく使われる「MeCab」と呼ばれるライブラリを使用します。事前にMeCab本体のインストールが必要です。下記からうまくダウンロードできない場合はミラーサイトなどをご利用ください。
| 公式ダウンロードページ(MeCab: Yet Another Part-of-Speech and Morphological Analyzer) |
通常、Python環境構築時はpipと呼ばれるコマンドを使って各種ライブラリをインストールします。Python連携機能においてもpipで直接インストールすることが可能ですが、Python Developer Toolと呼ばれるツールがあり、GUI操作でインストールが可能です!
Enterprise ManagerのアイコンからPython Developer Toolを起動してみましょう!
[設定]-[パッケージ管理]-[pipコマンドの実行]をクリック
[pipコマンド]のプルダウンメニューから「インストール(pip install)」を選択
パラメーターに「mecab-python3」と入力
[実行]をクリック
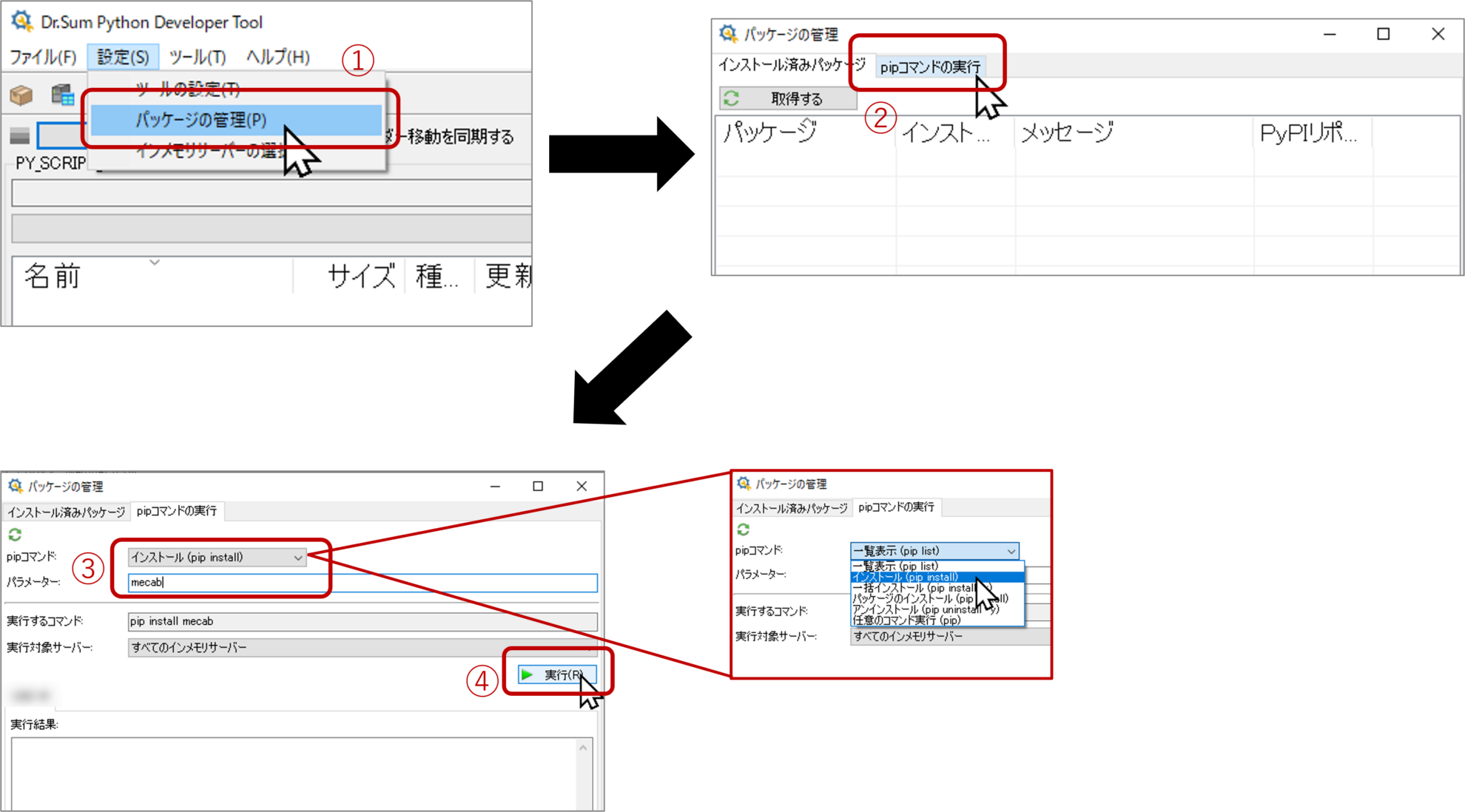
同様に以下のライブラリもインストールします。「パラメーター」に下記の文字列をそれぞれ入力し[実行]をクリック
pandas
unidic-lite
実行結果の最後に「Successfully installed MeCab=[Version]」などと表示されれば、問題なくインストールできています。以上で準備完了です!
事前準備は以上です。では、早速Pythonを実行してみましょう!と言いたいところですが、どうやってPythonスクリプトを実行すればよいでしょう?
外部のアプリケーション(特にMotionBoardなど)はDr.SumとSQLを通じてデータをやり取りします。この仕組みに則り、PythonスクリプトもSQLから実行できるようになっています。普段見慣れているSELECT文やUPDATE文と比べると特殊な書式になりますが、下記のようなSQL文になります。
SELECT *
FROM
udtf::serial_py(
restaurant_comments,
py_file_path='PY_SCRIPT_ROOT/morph_analysis.py',
func_name='proc_func',
args = ["コメント"],
schema_func_name='schema_func'
) TUPythonスクリプトも併せて見ると記述内容をイメージしやすいです。
# 結果表スキーマ取得関数
def schema_func(input_schema):
### <--- 省略 ---> ###
# 処理関数
def proc_func(context, input, *args):
### <--- 省略 ---> ###serial_py()の中身に渡す情報は下記のようになります。
対象のテーブル名
py_file_path=’Pythonスクリプトの配置場所’
func_name=’処理関数名’
args = [処理関数に渡すパラメータ]
schema_func_name=’結果表スキーマ取得関数名’
では、実際に形態素解析されたデータ(テーブル)が取得できるか確認してみましょう。SQL Executorを開き、「接続先データベース」にrestaurant_commentsテーブルを格納したデータベース(例では「Python連携」)を選択後、以下のSQLをコピー&ペーストして実行します。
SELECT *
FROM
udtf::serial_py(
restaurant_comments,
py_file_path='PY_SCRIPT_ROOT/morph_analysis.py',
func_name='proc_func',
args = ["コメント"],
schema_func_name='schema_func'
) TU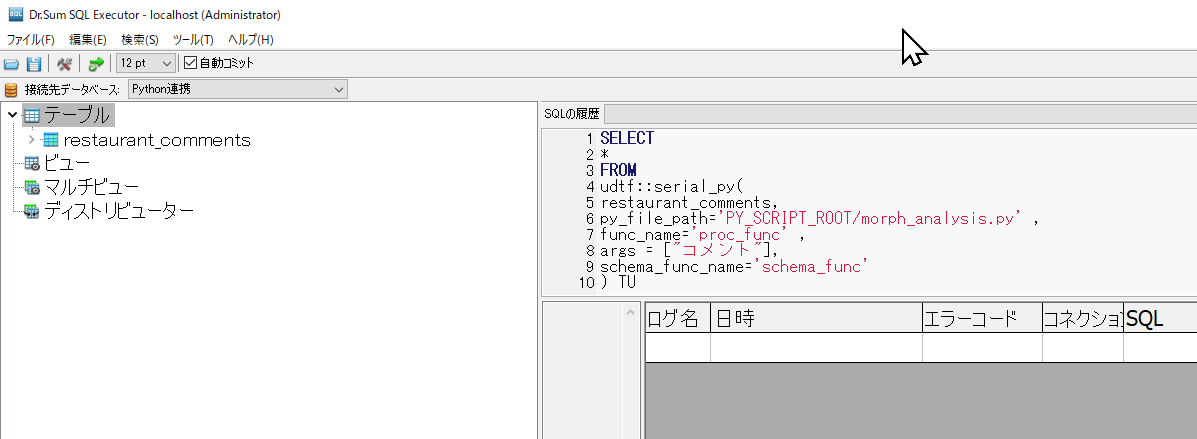
数秒程度の処理に時間を要しますが、問題がなければ元データに「品詞」、「単語」、「基本形」の3項目が追加されたテーブルが表示されます。
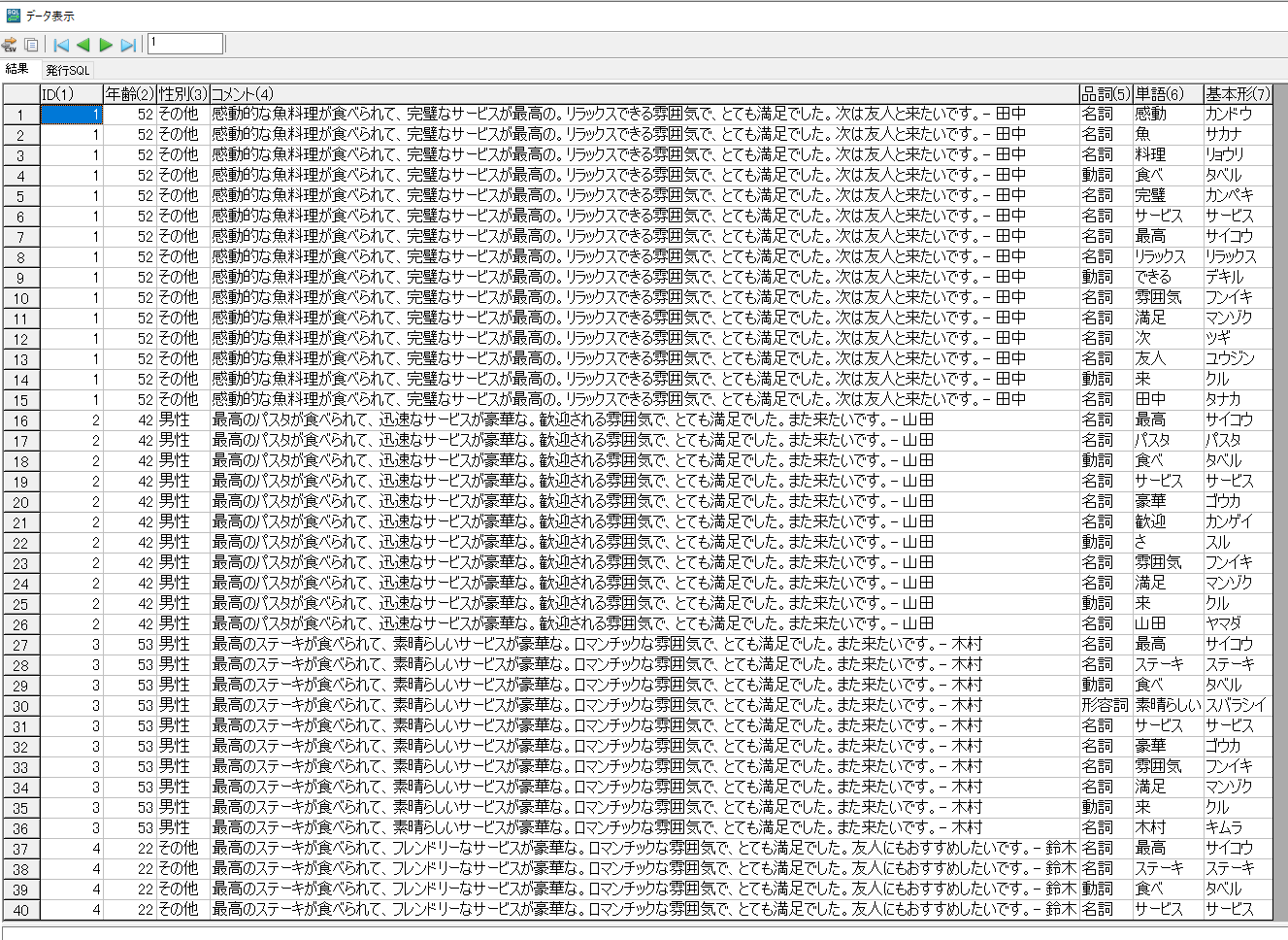
SQLを実行することでPythonの処理結果を取得できることを確認できました。最後に、このSQLをMotionBoardから実行・グラフ化する方法を紹介します。MotionBoardではユーザーが自由にSQLを記述し実行する機能として「カスタムビュー」があります。接続先のデータソースによって利用可否が異なりますが、Dr.Sumは利用可能です。
MotionBoardを起動
[管理]-[システム設定]-[接続/認証]-[外部接続]
メニューからDr.Sumの接続を選択-[カスタムビュー]タブをクリック-[新規作成]
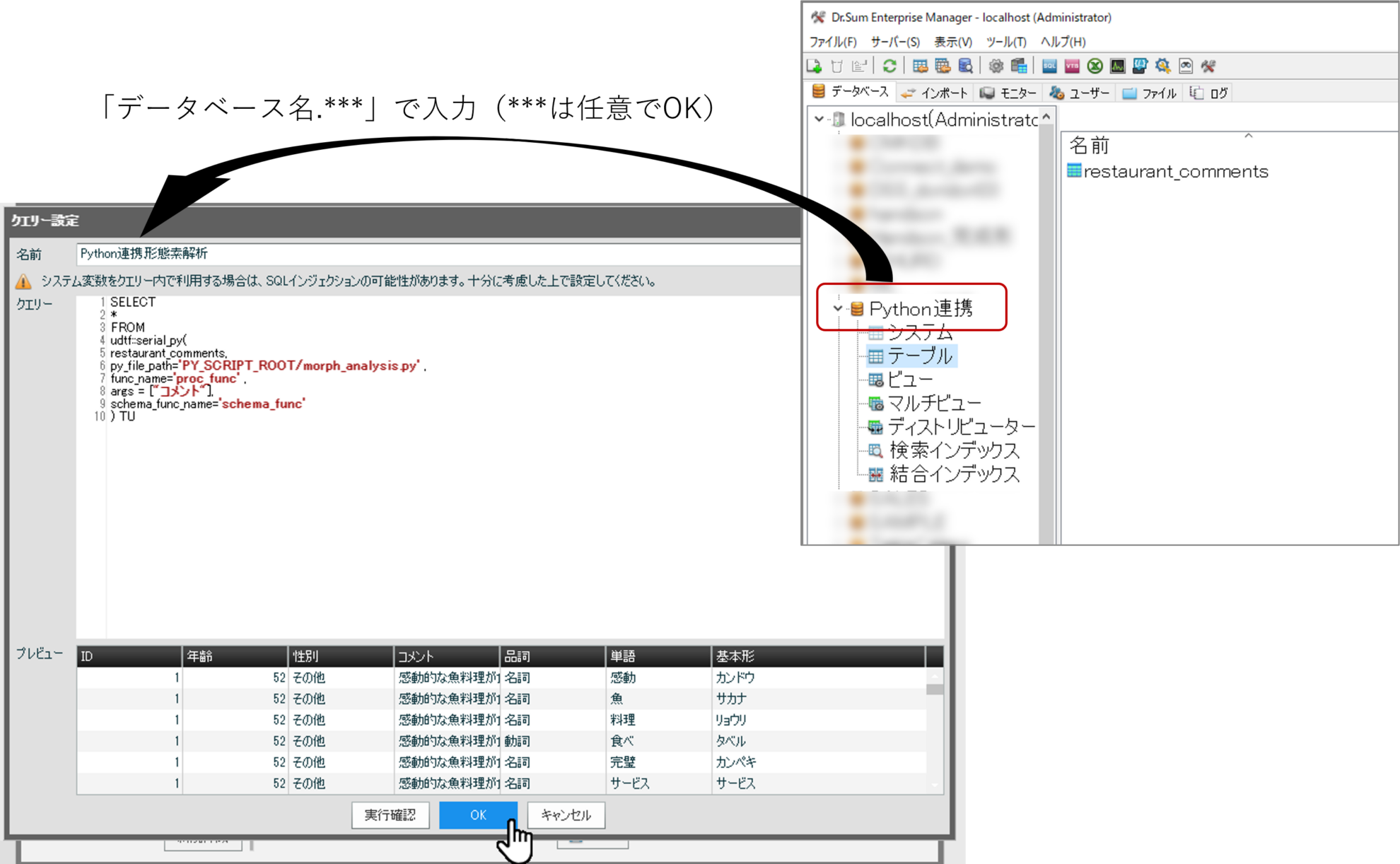
[名前]には「データベース名.***」の書式で入力(***は任意でOK、例では「Python連携.形態素解析」)。[クエリー]欄には前章で紹介したSQLを貼付
アイテムツールバーから「ワードクラウド」アイテムを選択・配置
データソースを作成します。データソース選択画面で[接続先]に対象のDr.Sumを選択
「CustomView」の中から、外部接続画面で作成したビューを選択
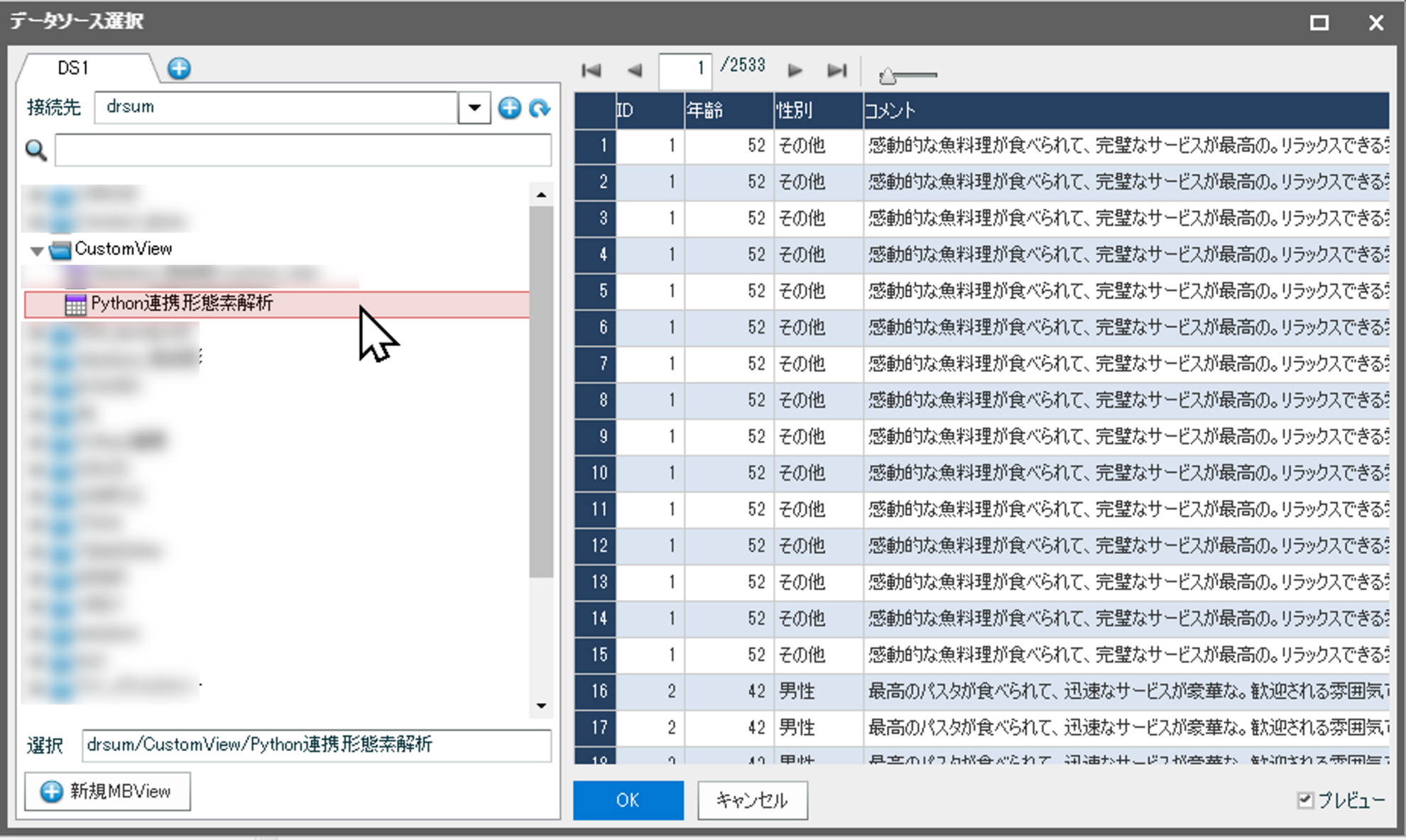
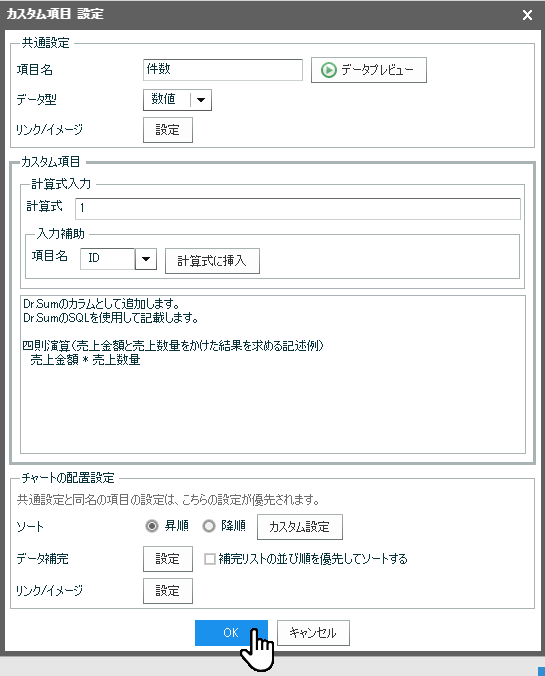
データソース編集画面では、件数をカウントするためカスタム項目を作成
[追加項目作成]-[カスタム項目]にチェックし[OK]をクリック。[項目名]は「件数」、[データ型]は「数値」、[計算式]は「1」を入力
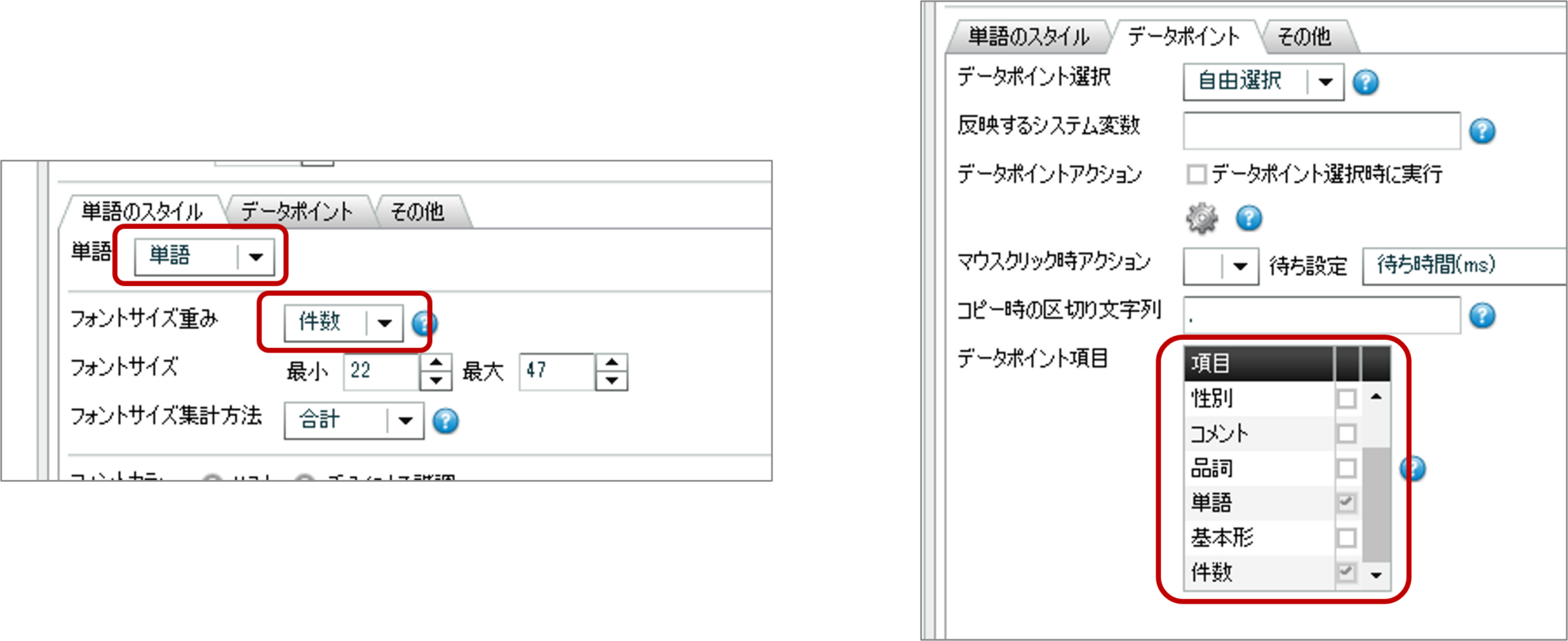
ワードクラウド表示方法の変更のため、ワードクラウド上でクリック後、[プロパティ]をクリック
[単語スタイル]タブ-[単語]に「単語」
[フォントサイズ重み]に「件数」を選択
[データポイント]タブ-[データポイント項目]にて「単語」及び「件数」以外のチェックを除外
以上の操作で、形態素解析の結果がワードクラウドアイテムに表示されることを確認します。
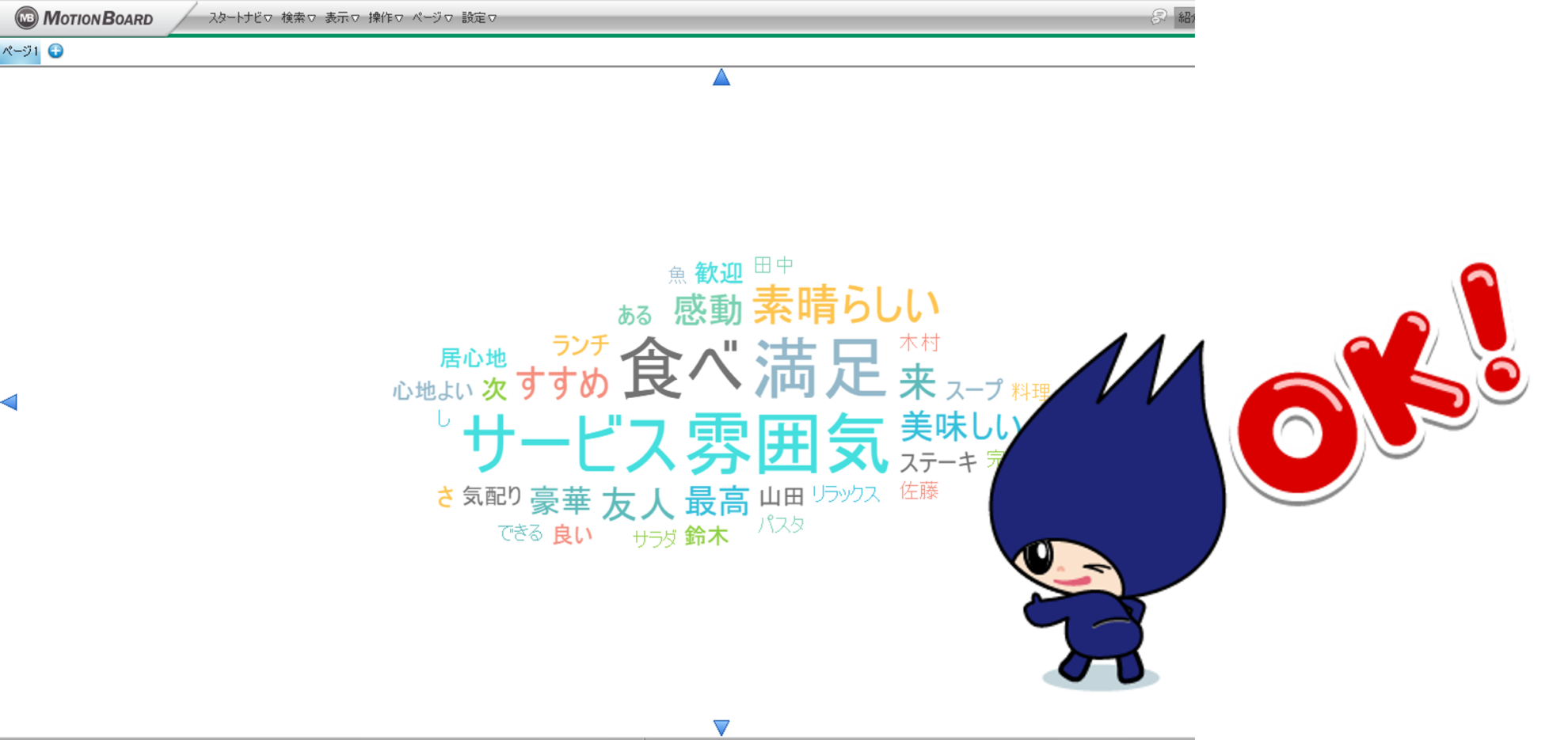
本記事ではPython連携機能を使ってコメントを形態素解析し、MotionBoardで可視化する方法を紹介しました。
Dr.Sumは大量のデータを蓄積できるため、例えば機械学習タスクを実行する上で非常に都合がよく、自由度高い分析を実現できます!一方で、データ量が多くなると解析に時間がかかるため、常に新しいデータに対してのみ学習を行う(オンライン学習)の仕組みを導入するのもよいですね。
Related article
Pick up
Ranking
Info