Search
Search


MENU
これまでの「invoiceAgentのWeb APIを使ってみる4」迄でログイン、アーカイブ、カスタムプロパティのセット、他についてご説明しました。
アーカイブされたファイルの量が増えてくると、次は必用なファイルを探し出す「検索」や検索にヒットしたファイルの「ダウンロード」のニーズも高まってくるのではないでしょうか。
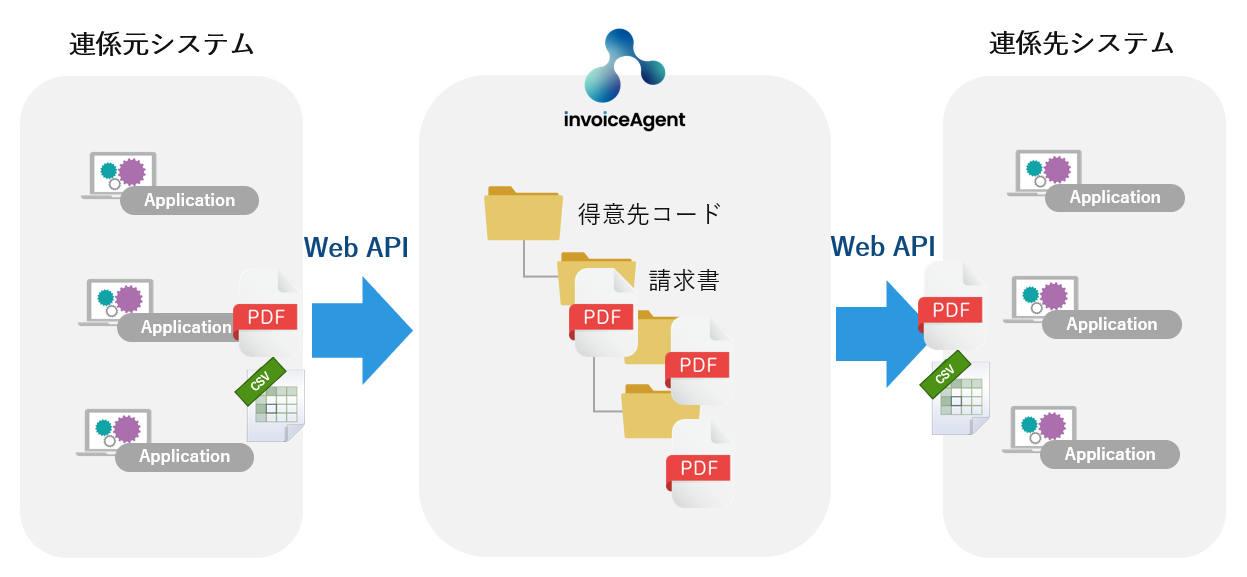
今回はinvoiceAgentにファイルが保管されていることを前提に、Web APIを利用したファイルの検索、ヒットしたファイルのダウンロード処理を実装します。
※ログイン/ログアウトの処理については今回は説明を割愛します。確認したい方は下記の記事を参考にしてください。
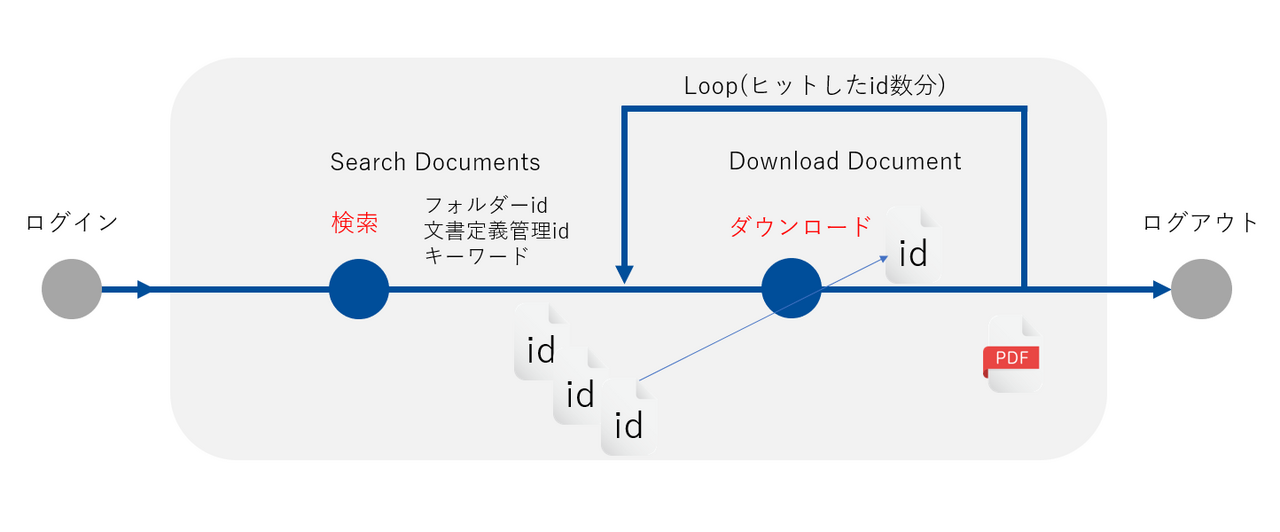
今回実装する処理の流れが以下の図です。
検索でドキュメントidを取得し、そのドキュメントidを指定してダウンロード処理を行います。
言語はJavaを前提にしておりますが、他の言語でも仕組みや考え方は同じです。
以下の解説を一通り実装したサンプルを本記事末尾のリンクよりダウンロードいただけます。
まずはAPIの確認です。
今回は Search Documents(Ver. 18)というAPIを利用します。
※今回は現時点でクラウド/オンプレどちらでも利用できるV18の利用としましたが、機能強化に伴い新たなバージョンのAPIが追加されることがあります。実装時には最新バージョンのAPIを確認してください。
詳細は以下マニュアルでご確認ください。
https://cs.wingarc.com/manual/ia/cloud/ja/3058200.html
APIの基本情報は以下の通りです。
| URI | http://<hostname>:44230/spa/service/search_v18/folder (オンプレ版invoiceAgentの場合) https://<hostname>.spa-cloud.com/spa/service/search_v18/folder (invoiceAgent Cloudの場合) |
| HTTPメソッド | POST |
| Content-Typeヘッダー | application/json |
検索条件をjson形式で送信するところがポイントです。
今回、指定する検索条件は以下の内容とします。
| 対象 | キー名 | 値 | 内容 |
| フォルダーID | folderIds/id | 103 | 該当のフォルダー配下のファイルを検索対象とする |
| 文書定義管理ID | conditions/docTypeId | 100 | 対象とする文書定義の文書管理IDを指定 |
| SVF検索フィールドの名称 | conditions/name | お客様名 | 指定するSVF検索フィールドの名称 |
| 検索ワード | conditions/value | 東京 | 検索キーワード |
フォルダーIDの値は該当フォルダーのプロパティで確認することができます。
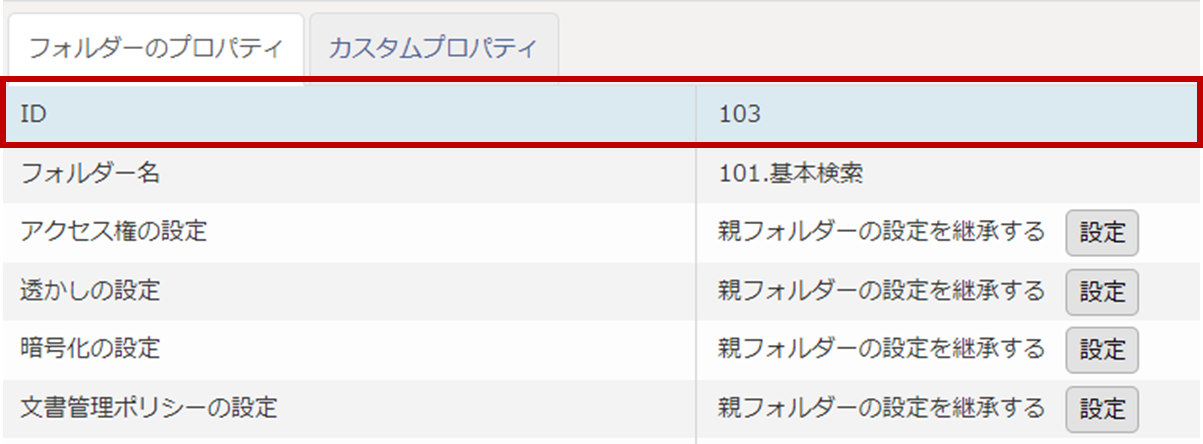
文書定義管理IDの値はサーバー環境の設定>文書定義の設定 にある「文書定義の設定」で確認することができます。
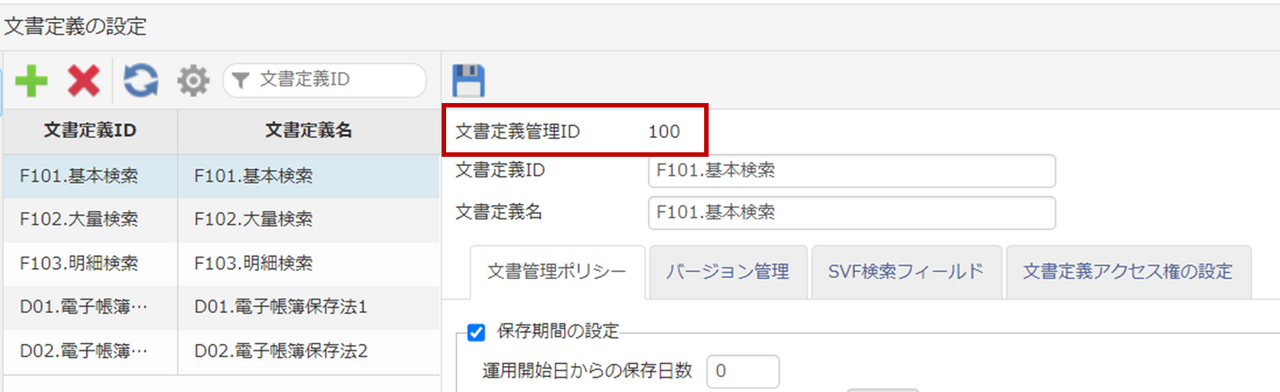
これらを送信するJSONで表すと以下のような内容になります。
{
"folderIds": [
{
"id": "103"
}
],
"operator": "AND",
"recursive": true,
"conditions": [
{
"conditionType": "svfField",
"name": "お客様名",
"docTypeId": "100",
"formName": "",
"dataType": "text",
"type": "contains",
"value": "東京"
}
]
}
それではプログラムで実装してみます。
まずはリクエストの送信です。
/** URLベース */
private static final String URL_BASE = "http://localhost:44230/spa/service";
/** 検索 */
private static final String SEARCH_DOCUMENTS = URL_BASE + "/search_v18/folder";
/** ダウンロード */
private static final String DOWNLOAD_DOCUMENT = URL_BASE + "/download_v4/";
~省略~
HttpURLConnection conn = null;
String forlderId = "103";
String docTypeId = "100";
String fieldName = "お客様名";
String sWord = "東京";
ArrayList<String> hitList = new ArrayList<String>();
try {
// 検索 フォルダーID 配下を対象に、SVF検索フィールドお客様名=東京 で検索
conn = (HttpURLConnection) new URL(SEARCH_DOCUMENTS).openConnection();
conn.setRequestMethod("POST");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setUseCaches(false);
conn.setAllowUserInteraction(false);
conn.setRequestProperty("Content-Type", "application/json");
conn.setRequestProperty("Cookie", param.getCookies());
if (param.getXsrfToken() != null && (param.getXsrfToken()).length() > 0 ) {
conn.setRequestProperty("X-XSRF-TOKEN", param.getXsrfToken());
conn.setRequestProperty("X-Requested-With", "XMLHttpRequest");
}
StringBuilder sb = new StringBuilder();
sb.append("{");
sb.append(" \"folderIds\": [");
sb.append(" {");
sb.append(" \"id\": \"" + forlderId + "\"");
sb.append(" }");
sb.append(" ],");
sb.append(" \"operator\": \"AND\",");
sb.append(" \"recursive\": true,");
sb.append(" \"conditions\": [");
sb.append(" {");
sb.append(" \"conditionType\": \"svfField\",");
sb.append(" \"name\": \"" + fieldName + "\",");
sb.append(" \"docTypeId\": \"" + docTypeId + "\",");
sb.append(" \"formName\": \"\",");
sb.append(" \"dataType\": \"text\",");
sb.append(" \"type\": \"contains\",");
sb.append(" \"value\": \"" + sWord + "\"");
sb.append(" }");
sb.append(" ]");
sb.append("}");
String reqJson = sb.toString();
try(BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(conn.getOutputStream(), "UTF-8"));
){
writer.write(reqJson);
writer.newLine();
}StringBuilder sb にJSONリクエストを格納しHttpURLConnectionを開いてsbの内容を送信する流れです。
正常に処理されると、レスポンスもJSON形式で以下のような内容が返ってきます。
{
"resultList": [
{
"type": "document",
"id": "105",
"parentId": "103",
"properties": {
"id": "105",
"name": "請求書3000_03.pdf",
"docpath": "/01.機能別/01.検索/101.基本検索",
"size": "7863146",
"pagecount": "3000",
"adddate": "2022-10-11T14:39:36.200+0900",
"adduser": "admin",
"adduserfullname": "Administrator",
"adduserdomain": "local",
"updatedate": "2022-10-11T14:39:36.200+0900",
"updateuser": "admin",
"updateuserfullname": "Administrator",
"updateuserdomain": "local",
~省略~
"loader_result_code": null,
"output_svffields_createdate": "",
"output_svffields_downloaddate": "",
"relate_info": "",
"tags": ""
},
"linkId": "-1",
~省略~
"federationId": null
}
]
}後続のダウンロード処理で必要なのは「resultList>id」のドキュメントIDみなので、これを取得する処理を実装します。
これまでの記事と同様にJacksonというライブラリを利用した処理になっています。
※JacksonのバージョンはV2.12.4を前提にしています。
※Jackson自体の利用方法については本記事では説明しませんが、有名なライブラリなので検索等していただければ利用方法の情報は直ぐに見つけることができるかと思います。
// 正常終了時 検索結果(JSON形式)を取得
ObjectMapper mapper = new ObjectMapper();
JsonNode document = mapper.readTree(conn.getInputStream());
//ファイルid / ファイル名 取得
System.out.println("検索結果");
for (JsonNode n : document.get("resultList")) {
if (n.get("type").asText().equals("document")) {
String docid = n.get("id").asText();
String docname = n.get("properties").get("name").asText();
System.out.println("------------------------------");
System.out.println("ドキュメントID: " + docid);
System.out.println("ファイル名: " + docname);
System.out.println("------------------------------");
hitList.add(docid);
}
}これで検索にヒットしたドキュメントidを取得することができました。
続いてはダウンロード処理を実装します。
APIの基本情報は以下の通りです。
| URI | http://<hostname>:44230/spa/service/download_v4/<id> (オンプレ版invoiceAgentの場合) https://<hostname>.spa-cloud.com/spa/service/download_v4/<id> (invoiceAgent Cloudの場合) |
| HTTPメソッド | POST |
| Content-Typeヘッダー | application/x-www-form-urlencoded |
リクエスト自体はとてもシンプルで、<id>の箇所に検索結果で取得したドキュメントIDが入る点だけ注意してください。
検索結果で複数のドキュメントIDが取得できた場合は、ダウンロード処理を繰り返し実行するよう実装する必用があります。
PDFファイルは複数ページあったり、画像が埋め込まれているとファイルサイズが大きくなる場合もあるので、メモリが不足しないように少しずつ読みながら書き込む処理を繰り返す必要があります。javaの場合はこのストリームの処理に少しなれが必要かもしれません。
実装は以下の通りです。
/** ダウンロード */
private static final String DOWNLOAD_DOCUMENT = URL_BASE + "/download_v4/";
~省略~
try {
// ダウンロード
conn = (HttpURLConnection) new URL(DOWNLOAD_DOCUMENT + docId).openConnection();
System.out.println("URL: " + DOWNLOAD_DOCUMENT + docId);
conn.setRequestMethod("POST");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setUseCaches(false);
conn.setAllowUserInteraction(false);
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
conn.setRequestProperty("Cookie", param.getCookies());
if (param.getXsrfToken() != null && (param.getXsrfToken()).length() > 0 ) {
conn.setRequestProperty("X-XSRF-TOKEN", param.getXsrfToken());
conn.setRequestProperty("X-Requested-With", "XMLHttpRequest");
}
conn.connect();
// 正常に終了することができなかった場合
if (conn.getResponseCode() != 200) {
// HTTPステータスとSPA独自のエラーコードを取得できる
int errCode = conn.getHeaderFieldInt("X-Spa-Error-Code", -1);
System.out.println("HTTP ErrorCode[" + conn.getResponseCode() + "]");
System.out.println("SPA ErrorCode[" + errCode + "]");
String errMsg = conn.getHeaderField("X-Spa-Error-Message");
if (errMsg != null) {
System.out.println("SPA Error Message[" + URLDecoder.decode(errMsg, "UTF-8") + "]");
}
throw new Exception(conn.getResponseMessage());
}
//ファイルダウンロード
String contentType = conn.getContentType();
String raw = conn.getHeaderField("Content-Disposition");
String fileName = getFileName(raw);
DataInputStream dataInStream = new DataInputStream(conn.getInputStream());
DataOutputStream dataOutStream = new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream(DOWNLOAD_FOLDER_PATH + fileName)));
// Read Data
byte[] b = new byte[4096];
int readByte = 0;
while (-1 != (readByte = dataInStream.read(b))) {
dataOutStream.write(b, 0, readByte);
}
// Close Stream
dataInStream.close();
dataOutStream.close();
System.out.println("検索結果にヒットしたファイルをダウンロードし、以下フォルダーへ保存しました。");
System.out.println(DOWNLOAD_FOLDER_PATH + fileName);
ファイル名については検索の時点で取得しておき利用するのも良いのですが、今回はダウンロード時のContent-Dispositionから取得するよう実装しています。
private static final String getFileName(String disposition) throws Exception {
String fileName = null;
String[] split = disposition.split(";");
for(String w : split) {
w = w.trim().toLowerCase();
if (w.startsWith("filename")) {
//ファイル名名取得
String rw = w.split("=")[1];
//文字コード
String enc = rw.split("''")[0];
if (enc != null && enc.length() > 0) {
rw = rw.split("''")[1];
}
if (enc != null && enc.length() > 0) {
//エンコード指定あり デコード処理
fileName = URLDecoder.decode(rw, enc);
} else {
//エンコード指定なければデコードなし
fileName = rw;
}
}
}
return fileName;
}実装は以上になります。
mainメソッドを呼び出して、実行してみます。
コンソールには以下のような内容が表示されます。
1.ログイン正常終了
2.検索開始
検索結果
——————————
ドキュメントID: 105
ファイル名: 請求書3000_03.pdf
——————————
検索完了
3.ファイルダウンロード開始
URL: http://localhost:44230/spa/service/download_v4/105
検索結果にヒットしたファイルをダウンロードし、以下フォルダーへ保存しました。
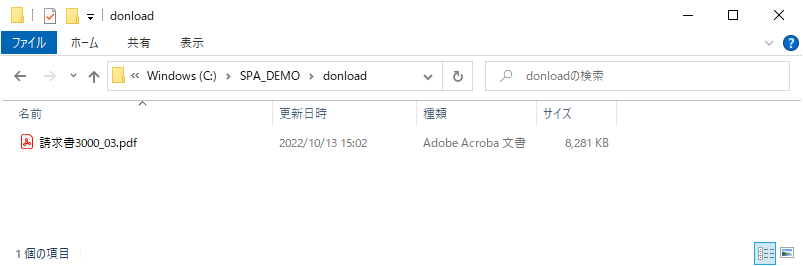
C:\SPA_DEMO\donload\請求書3000_03.pdf
ファイルダウンロード終了
4.ログアウト正常終了
終了します
保存先のフォルダーを確認すると以下のように保存されています。
今回は検索とダウンロード処理を実装してみました。
検索はSVF検索フィールドを対象として実装しましたが、全文検索やカスタムプロパティの検索も同じAPIを利用して実装することができます。
ダウンロード処理の実装についてもSVF検索フィールドをCSVダウンロードする際等、流用できるケースが多いのではないかと思います。
今回ご説明した一連の処理を実行できるサンプルのソースファイルを以下のリンクからダウンロードいただけますので参考にしてみてくださいね。
※ダウンロードボタンをクリックするとzip形式でダウンロードいただけます。解凍してご確認ください。
※ソースファイルの文字コードはUTF-8です。
※本記事の情報は、2022年10月17日現在のものです。(SPA V10.8.0 / SPA Cloud Ver.10.8.0.1008)
Related article
Pick up
Ranking
Info