Search
Search


MENU
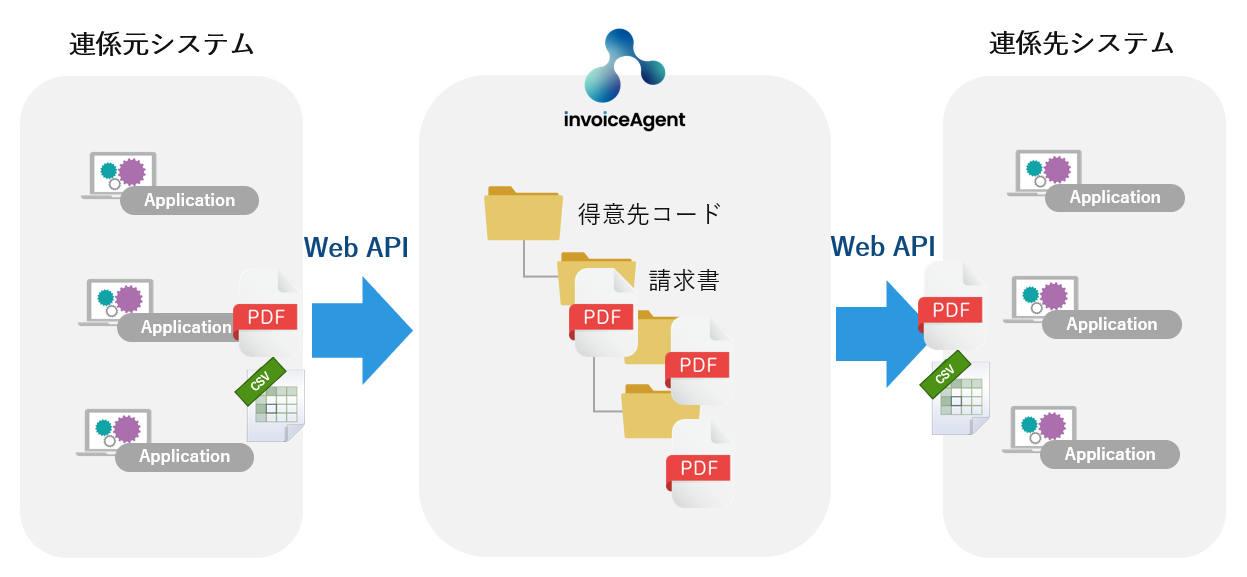
invoiceAgentのOCR機能を使ってテキスト化した値を2次活用するためにはそのテキストを抽出して、システムやデータベースへインポートする必要があります。invoiceAgentの標準機能としては画面上から操作してCSVダウンロードして対応することになりますが、日々の業務ともなると負担になってしまうのでどうせなら自動化して業務効率化したいですよね。
今回はinvoiceAgentの特定のフォルダーにOCR済みのPDFファイルが保管されていることを前提に、Web APIを利用したSVF検索フィールドのCSV出力とダウンロード処理を実装します。
※ログイン/ログアウトの処理については今回は説明を割愛します。確認したい方は下記の記事を参考にしてください。
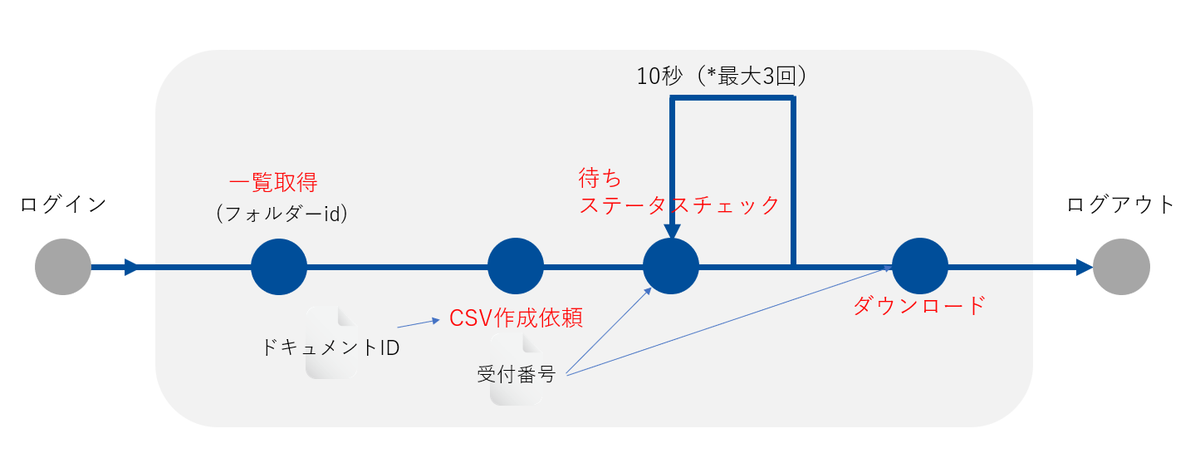
今回実装する処理の流れが以下の図です。
検索でドキュメントidを取得し、そのドキュメントidを指定してCSV作成依頼を行います。
CSV生成は非同期で実行されるので、直ぐにダウンロード処理を行うのではなく待機する処理と、作成状況のステータスチェックを行います。
今回は10秒待機させてステータスチェックを行い、完了していなければさらに10秒待たせます。
最大で合計30秒待たせて完了していればダウンロード処理を行います。完了しなければ処理を終了します。
今回はとあるフォルダー配下にあるPDFファイルを対象にCSV出力を行うことを前提にしますので、フォルダー配下にあるファイル一覧を取得するAPI、Documents List(Ver. 15)を使用します。
URI | http://<hostname>:44230/spa/service/documents_v15/<id>/list(オンプレ版invoiceAgentの場合) https://<hostname>.spa-cloud.com/spa/service/documents_v15/<id>/list(invoiceAgent Cloudの場合) |
HTTPメソッド | POST |
Content-Typeヘッダー | application/x-www-form-urlencoded |
リクエスト自体はとてもシンプルで、URLの<id>の箇所にフォルダーIDが入る点だけ注意してください。
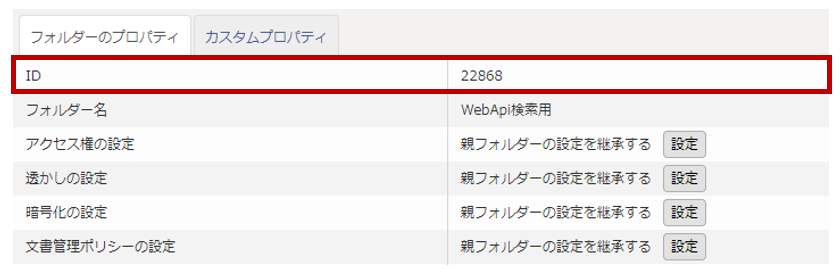
フォルダーIDの値は該当フォルダーのプロパティで確認することができます。
今回はフォルダーIDを「22868」とします。
フォルダーIDはフォルダーの名称やパス等を条件にWeb APIで取得することもできます。
マニュアルにはフォルダー操作系のWeb APIも解説があるのでご確認ください。
1.10. フォルダー操作 | invoiceAgent V10.8.1マニュアル
https://cs.wingarc.com/manual/ia/doc/10.8.1/ja/1569992.html
それではプログラムで実装してみます。
まずはリクエストの送信です。
/** ファイルリスト */
private static final String DOCUMENTS_LIST = URL_BASE + "/documents_v15/";
~省略~
HttpURLConnection conn = null;
String forlderId = "22868";
List documentIds = new ArrayList();
try {
//フォルダーID 配下のファイル一覧を取得
URL url = new URL(DOCUMENTS_LIST + forlderId + "/list");
conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("POST");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setUseCaches(false);
conn.setAllowUserInteraction(false);
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
//
conn.setRequestProperty("Cookie", param.getCookies());
// JSON形式で出力する指示
conn.setRequestProperty("Accept", "application/json");
System.out.println(param.getCookies());
if (param.getXsrfToken() != null && (param.getXsrfToken()).length() > 0) {
conn.setRequestProperty("X-XSRF-TOKEN", param.getXsrfToken());
conn.setRequestProperty("X-Requested-With", "XMLHttpRequest");
}
URLオブジェクトを生成する際にフォルダーIDを指定しています。
正常に処理されると、レスポンスはJSON形式で以下のような内容が返ってきます。
今回必要なのは「id」のみです。
{
"documentList": [
{
"type": "document",
"id": "76086",
"parentId": "22868",
"properties": {
"id": "76086",
"name": "見積書_2019110001_100001_城戸尚司.pdf",
"docpath": "/kitade.h/WebApi検索用",
"size": "48724",
"pagecount": "1",
"adddate": "2022-03-30T16:35:57.520+0900",
"adduser": "admin",
"adduserfullname": "Administrator",
"adduserdomain": "local",
"updatedate": "2022-03-30T16:35:57.520+0900",
"updateuser": "admin",
"updateuserfullname": "Administrator",
"updateuserdomain": "local",
"filetype": "0",
"linkpath": null,
~省略~
},
"linkId": "-1",
"propertyEntityVersion": 0,
"documentEntityVersion": 0,
"annotationEntityVersion": 0,
"pagememoEntityVersion": 0,
"svffieldEntityVersion": 0,
"customProperties": {},
"federationId": null
}
]
}
後続のダウンロード処理で必要なのは「documentList>id」のドキュメントIDみなので、これを取得する処理を実装します。
これまでの記事と同様にJacksonというライブラリを利用した処理になっています。
※JacksonのバージョンはV2.12.4を前提にしています。
※Jackson自体の利用方法については本記事では説明しませんが、有名なライブラリなので検索等していただければ利用方法の情報は直ぐに見つけることができるかと思います。
ObjectMapper mapper = new ObjectMapper();
JsonNode document = mapper.readTree(conn.getInputStream());
System.out.println("document:" + document);
//ファイル名取得
for (JsonNode n : document.get("documentList")) {
if (n.get("type").asText().equals("document")) {
String docid = n.get("id").asText();
documentIds.add(docid);
System.out.println("DocId: " + docid);
}
}
} catch (Exception e) {
throw e;
} finally {
conn.disconnect();
}
return documentIds;
Documents Listで取得したドキュメントIDを指定してファイルの作成処理を依頼します。
利用するAPIはRequest Search Data Csv From Documents(Ver. 13)を使用します。
APIの基本情報は以下の通りです。
| URI | http://<hostname>:44230/spa/service/output_v13/searchdatacsv/request/document(オンプレ版invoiceAgentの場合) https://<hostname>.spa-cloud.com/spa/service/output_v13/searchdatacsv/request/document(invoiceAgent Cloudの場合) |
HTTPメソッド | POST |
Content-Typeヘッダー | application/json |
リクエストはjson形式で行い、documentIdsに取得したドキュメントIDをカンマ区切りで、zipFileNameにはダウンロードする際のファイル名(zip形式)を指定します。
リクエストJSONの例
{
"documentIds": [
"76086",
"76087",
"76084",
"76085"
],
"headerNameType": "searchName",
"outputMethod": "splitFile",
"splitFileLimitBreak": 0,
"zipFileName": "SearchData.zip"
}
ではこのJSONリクエストをプログラムから送信します。
/** CSVデータ作成依頼用のURL */
private static final String CSV_REQURL = URL_BASE + "/output_v13/searchdatacsv/request/document";
~省略~
// HttpURLConnectionの作成
URL url = new URL(CSV_REQURL);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
String requestId = null;
try {
// HttpURLConnectionの各種設定
conn.setRequestMethod("POST");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setUseCaches(false);
conn.setAllowUserInteraction(false);
conn.setRequestProperty("Content-Type", "application/json");
//
conn.setRequestProperty("Cookie", param.getCookies());
if (param.getXsrfToken() != null && (param.getXsrfToken()).length() > 0) {
conn.setRequestProperty("X-XSRF-TOKEN", param.getXsrfToken());
conn.setRequestProperty("X-Requested-With", "XMLHttpRequest");
}
// JSON形式で出力する指示
conn.setRequestProperty("Accept", "application/json");
// パラメーターをセットする
try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(conn.getOutputStream(), "UTF-8"))) {
//IDのリスト作成 "123","456","789"
StringBuffer idbuf = new StringBuffer();
for (Iterator itr = idList.iterator(); itr.hasNext();) {
String s = itr.next();
idbuf.append("\"" + s + "\"");
if (itr.hasNext()) {
idbuf.append(",");
}
}
StringBuffer buf = new StringBuffer();
buf.append("{");
buf.append(" \"documentIds\": [");
buf.append(" %s");
buf.append(" ],");
buf.append(" \"headerNameType\": \"searchName\",");
buf.append(" \"outputMethod\": \"splitFile\",");
buf.append(" \"splitFileLimitBreak\": 0,");
buf.append(" \"zipFileName\": \"%s\"");
buf.append("}");
String reqJson = String.format(buf.toString(),idbuf.toString(), DOWNLOAD_CSV_FILENAME);
System.out.println(reqJson);
writer.write(reqJson);
}
レスポンスのJSONからrequestId(受付番号)を取得します。
JSONレスポンスの例
{"requestId":"1115"}プログラムではこのrequestId(受付番号)を取得するよう実装します。
ObjectMapper mapper = new ObjectMapper();
JsonNode document = mapper.readTree(conn.getInputStream());
// リクエストID取得
requestId = document.get("requestId").asText();
} finally {
conn.disconnect();
}
return requestId;
CSVの生成リクエストは非同期で実行されるため、この後の処理は一定時間待機させた後で、CSVファイル生成のステータスを確認し完了していたら次の処理へ進めます。
待機させるのはThread.sleepメソッドを使用します。
以下は10秒待機させてからこの後作成するcheckStatusメソッドで作成完了しているかステータスのチェックを行います。
ステータスが完了になっていなければ繰り返し処理を行い(最大3回)、それでも完了しなければ処理を終了します。
//4. 10秒待ち 処理完了を待機。10秒*3回待っても終わらない場合は終了。
int cnt = 0;
while (true) {
if (cnt >= 3) {
System.out.println("30秒以内にCSVの作成が完了しませんでした。");
return;
}
Thread.sleep(10 * 1000);
if (csvDownload.checkStatus(param, id)) {
break;
}
cnt++;
}
System.out.println("4.CSVファイル作成完了");
CSV作成のステータスチェックはOutput Search Data Csv Status Get(Ver. 2)を使用します。
| URI | http://<hostname>:44230/spa/service/output_v2/searchdatacsv/status/<id>(オンプレ版invoiceAgentの場合) https://<hostname>.spa-cloud.com/spa/service/output_v2/searchdatacsv/status/<id>(invoiceAgent Cloudの場合) |
| HTTPメソッド | GET |
URLのID部分にはRequest Search Data Csv From Documents(Ver. 13)で取得したrequestId(受付番号)を指定します。
/** CSV作成ステータス確認 */
private static final String CSV_STATUS = URL_BASE + "/output_v2/searchdatacsv/status/";
~省略~
// HttpURLConnectionの作成
URL url = new URL(CSV_STATUS + id);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
boolean status = false;
try {
// HttpURLConnectionの各種設定
conn.setRequestMethod("GET");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setUseCaches(false);
conn.setAllowUserInteraction(false);
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
//
conn.setRequestProperty("Cookie", param.getCookies());
if (param.getXsrfToken() != null && (param.getXsrfToken()).length() > 0) {
conn.setRequestProperty("X-XSRF-TOKEN", param.getXsrfToken());
conn.setRequestProperty("X-Requested-With", "XMLHttpRequest");
}
// JSON形式で出力する指示
conn.setRequestProperty("Accept", "application/json");
ステータスの値「1」が完了を意味するので、その場合に「status = true;」として返却します。
ObjectMapper mapper = new ObjectMapper();
JsonNode document = mapper.readTree(conn.getInputStream());
System.out.println("document:" + document);
//ファイル名取得
String statusStr = document.get("status").asText();
System.out.println("CSV作成ステータス: " + statusStr);
if (statusStr.equals("1")) {
//処理済み
status = true;
}
} finally {
conn.disconnect();
}
return status;
Output Search Data Csv Get(Ver. 2)を使用しCSVファイルのダウンロードを行います。
| URI | http://<hostname>:44230/spa/service/output_v2/searchdatacsv/<id>(オンプレ版invoiceAgentの場合) https://<hostname>.spa-cloud.com/spa/service/output_v2/searchdatacsv/<id>(invoiceAgent Cloudの場合) |
| HTTPメソッド | GET |
URLのID部分にはRequest Search Data Csv From Documents(Ver. 13)で取得したrequestId(受付番号)を指定します。
それではプログラム実装します。他のAPIの利用の仕方と同じパターンで特に難しい点はないと思います。
// HttpURLConnectionの作成
URL url = new URL(CSVOUTPUT_URL + id);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
//
String fileName = null;
try {
// HttpURLConnectionの各種設定
conn.setRequestMethod("GET");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setUseCaches(false);
conn.setAllowUserInteraction(false);
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
//
conn.setRequestProperty("Cookie", param.getCookies());
if (param.getXsrfToken() != null && (param.getXsrfToken()).length() > 0) {
conn.setRequestProperty("X-XSRF-TOKEN", param.getXsrfToken());
conn.setRequestProperty("X-Requested-With", "XMLHttpRequest");
}
// JSON形式で出力する指示
conn.setRequestProperty("Accept", "application/json");
ストリームからファイルをダウンロードし、ファイルへ出力します。
zip形式になっているので必要に応じて解凍処理を行います。
//ファイルダウンロード
String contentType = conn.getContentType();
String raw = conn.getHeaderField("Content-Disposition");
fileName = getFileName(raw);
DataInputStream dataInStream = new DataInputStream(conn.getInputStream());
DataOutputStream dataOutStream = new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream(DOWNLOAD_FOLDER_PATH + fileName)));
// Read Data
byte[] b = new byte[4096];
int readByte = 0;
while (-1 != (readByte = dataInStream.read(b))) {
dataOutStream.write(b, 0, readByte);
}
// Close Stream
dataInStream.close();
dataOutStream.close();
System.out.println("CSVファイルをダウンロードし、以下フォルダーへ保存しました。");
System.out.println(DOWNLOAD_FOLDER_PATH + fileName);
//拡張子がzipの場合、解凍処理する
if (ext.equals(".zip")) {
//zipファイル解凍 + ファイル名リネーム
unZip(DOWNLOAD_FOLDER_PATH + fileName, fileName);
}
mainメソッドを呼び出して、実行してみます。
コンソールには以下のような内容が表示されます。
1.ログイン正常終了
XSRF-TOKEN=EBA0-TPK3-2PBW-NGF6-K28J-OMPK-6F4S-IZB8; JSESSIONID=F7F9792692961C6F881B1D53DBCC0D0B; AWSALBCORS=8BWlK5W2maDOvXlN04g8dm4qG2VZRJLchHWASvbo0MAqJqMdleSSfr5hZKrmnaQnInxlcZx1mEeHmpbN85L4eUvcnv0yr1p3j+zOUhCqOSp5QepmexVfmnVsjiPk; AWSALB=8BWlK5W2maDOvXlN04g8dm4qG2VZRJLchHWASvbo0MAqJqMdleSSfr5hZKrmnaQnInxlcZx1mEeHmpbN85L4eUvcnv0yr1p3j+zOUhCqOSp5QepmexVfmnVsjiPk;
2.ファイル一覧取得完了
{ "documentIds": [ "76086","76087","76088","76089","76090","76091","76062","76063","76064","76065","76066","76067","76068","76069","76070","76071","76072","76073","76074","76075","76076","76077","76078","76079","76080","76081","76082","76083","76084","76085" ], "headerNameType": "searchName", "outputMethod": "splitFile", "splitFileLimitBreak": 0, "zipFileName": "SearchData.zip"}
CSV作成リクエスト:{"requestId":"1118"}
受付番号: 1118
3.CSVファイル作成依頼完了
document:{"status":1,"id":"1118","acceptDate":"2023-03-17T00:00:00.095+0900","endDate":"2023-03-17T00:00:01.290+0900","fileName":"SearchData.zip","csvFileName":"mitsumori01_.csv","errorCode":"","errorMessage":""}
CSV作成ステータス: 1
4.CSVファイル作成完了
CSVファイルをダウンロードし、以下フォルダーへ保存しました。
C:\invoiceAgent_sample\donload\searchdata.zip
5.CSVファイルダウンロード完了
6.ログアウト正常終了
終了します
今回の実装は少しボリュームがありましたね。
ただリクエスト送信時のパラメータの扱いがラクなものが多かったり、
ファイルのダウンロードも前回の記事で実装していたので苦労はなかったのではないかと思います。
今回ご説明した一連の処理を実行できるサンプルのソースファイルを以下のリンクからダウンロードいただけますので参考にしてみてくださいね。
※ダウンロードボタンをクリックするとzip形式でダウンロードいただけます。解凍してご確認ください。
※ソースファイルの文字コードはUTF-8です。
※本記事の情報は、2023年03月20日現在のものです。(invoiceAgent V10.8.1 / (invoiceAgent Cloud Ver.10.8.1.1302)
Related article
Pick up
Ranking
Info