Search
Search


MENU
これまでの記事ではConnect for Java APIのアーカイブや検索の処理についてご説明しました。
今回はinvoiceAgentのOCR機能を使ってテキスト化した値を2次活用するために必要なSVF検索フィールドのダウンロード処理についてご説明します。
ダウンロードしたデータはCSV形式になっているのでシステムやデータベースへインポートして活用することができますね。
今回の処理は以下の流れで行います。
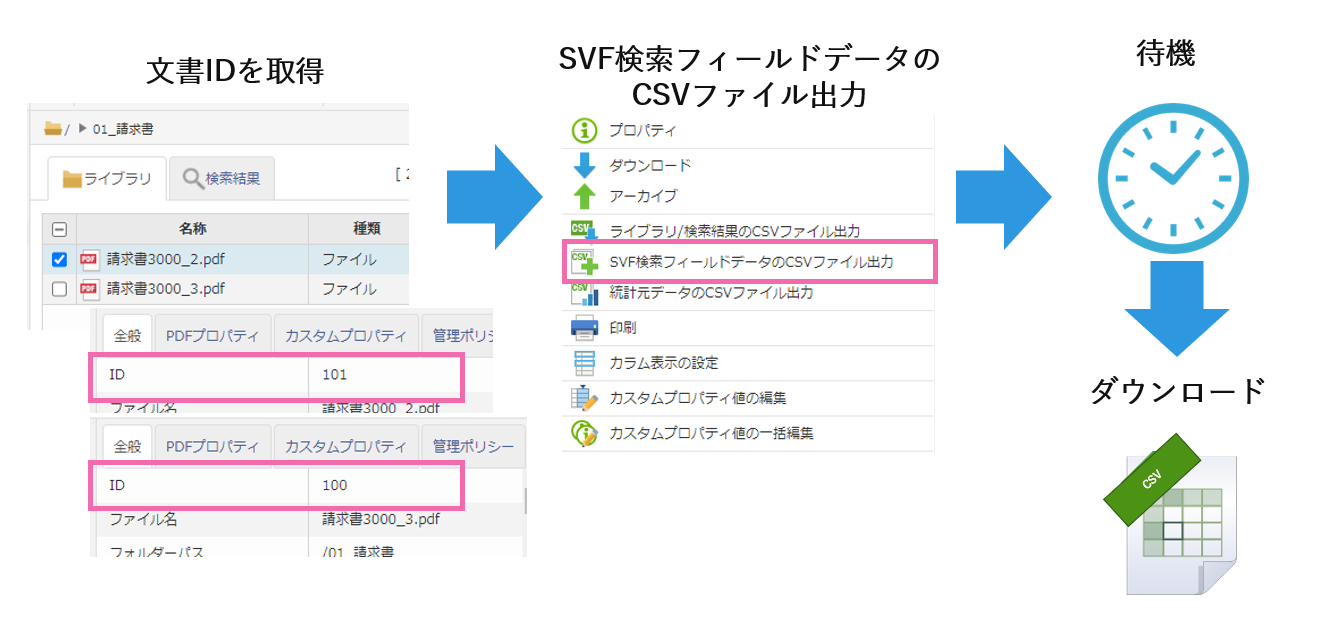
これらの処理をメインメソッドに記載すると以下のような流れになります。
//1.ログイン
C4JApi3FieldDataDownload cls = new C4JApi3FieldDataDownload();
try {
cls.login();
System.out.println("1.ログイン成功");
} catch (SpaClientException e) {
System.out.println("ログインに失敗しました。ID/PWを確認してください。");
e.printStackTrace();
return;
}
//2.フォルダー配下にある全ファイルの文書IDを取得
System.out.println("2.フォルダー配下にある全ファイルの文書IDを取得");
List dlist = cls.getDocumentIdList("101");
for (String did : dlist) {
System.out.println(" 文書ID = " + did);
}
//3.フィールドデータの生成リクエストを送信
long rId = cls.requestCsvFromDocuments(dlist);
System.out.println(" 受付ID = " + rId);
//4. 10秒待ち 処理完了を待つ。10秒*3回待っても終わらない場合は終了。
int cnt = 0;
while (true) {
if (cnt >= 3) {
System.out.println("30秒以内にCSVの生成が完了しませんでした。");
return;
}
System.out.println(" 10秒待機します。" + (cnt + 1) + "回目");
Thread.sleep(10 * 1000);
if (cls.checkStatus(rId)) {
break;
}
cnt++;
}
System.out.println("4.CSVファイル生成完了");
//5. 生成したCSVファイルのダウンロード
cls.getCsv(rId);
System.out.println("5.CSVダウンロード完了");
//9.ログアウト
cls.logout();
System.out.println("9.ログアウト 成功");
1.ログイン、9.ログアウトはこれまでの記事で解説したので省略させていただき2~5の処理についてご説明します。
本記事の解説を一通り実装したサンプルを末尾のリンクよりダウンロードいただけます。
シンプルにDocumentsResource#listで取得できます。
/**
* フォルダーID配下にある全ファイルの文書IDを取得
*
* @param folderId フォルダーID
* @return 文書IDのリスト
* @throws SpaClientException
* @throws IOException
*/
public List<String> getDocumentIdList(String folderId) throws SpaClientException,IOException{
List<String> list = new ArrayList<String>();
DocumentsResource dr = new DocumentsResource(client__);
DocumentList dlist = dr.list(Long.parseLong(folderId), false);
//DocumentContentからIDを取得
for(DocumentContent dcon: dlist){
String id = dcon.getId();
list.add(id);
}
return list;
}
戻り値のDocumentListからDocumentContentを取得、さらにDocumentContent#getIdで文書IDを取得できます。
次の処理のためList<String>に格納しておきます。
今回はこのようにフォルダー配下の文書ID一覧を取得しましたが、前記事で実装した検索によって取得した文書IDと組み合わせて使うのも実用的です。
使い方に一癖あるのがこの処理です。
OutputResource#requestCsvFromDocuments(RequestSearchDataCsvFromDocuments) で処理を行います。
その際にRequestSearchDataCsvFromDocumentsに対して何のパラメータをセットすべきなのかがJavaDocだけでは見えないと思います。
/**
* SVF検索フィールドのCSV出力をリクエストする
*
* @param ids フォルダーIDのリスト
* @return 文書IDのリスト
* @throws SpaClientException
* @throws IOException
*/
public long requestCsvFromDocuments(List ids) throws SpaClientException,IOException{
OutputResource or = new OutputResource(client__);
RequestSearchDataCsvFromDocuments rsdc = new RequestSearchDataCsvFromDocuments();
rsdc.getCommonParts().setDocumentIds(ids);
rsdc.getCommonParts().setZipFileName(DOWNLOAD_CSV_FILENAME);
rsdc.getOption().setSplitFileLimitBreak(0);
//実行
long ret = or.requestCsvFromDocuments(rsdc);
return ret;
}
生成したRequestSearchDataCsvFromDocumentsに対してgetCommonPartsしてから値をセットしています。
いろいろと細かな条件を指定できますが、今回は必要最低限のパラメータを指定して実装しました。
CSVの列項目を制御したい場合はOutputColumnを使用し
RequestSearchDataCsvFromDocuments.getOption().setOutputColumns(List<OutputColumn>)してください。
戻り値の「受付ID」は後続の処理で使用します。
待機処理は上記のメインメソッドをご確認ください。
ステータスチェックの実装は以下の通りです。
/**
* SVF検索フィールド生成のステータスをチェックする
* @param rId 受付ID
* @return
*/
public boolean checkStatus(long rId) throws SpaClientException,IOException{
OutputResource or = new OutputResource(client__);
DownloadFileEntry dfe = or.getOutputSearchDataCsvStatusGet(rId);
if(dfe.getStatus() == 1) {
//1完了
return true;
}
//0処理中,2異常終了
return false;
}
OutputResource#getOutputSearchDataCsvStatusGet(受付ID)よりDownloadFileEntry#getStatusで取得できます。
「1」のステータスであれば完了となります。
OutputResource#getOutputSearchDataCsv(受付ID)でファイルをダウンロードします。
#getOutputSearchDataCsv(受付ID,DownloadFile.FileType.csv)の第二引数でCSV形式を指定しています。
ZIP形式にしたい場合はDownloadFile.FileType.zipとします。
/**
* 生成したCSVファイルのダウンロード
* @param rId 受付ID
* @throws SpaClientException
* @throws IOException
*/
public void getCsv(long rId) throws SpaClientException,IOException{
OutputResource or = new OutputResource(client__);
//CSVでのダウンロードを指定(FileType.csv or FileType.zipを指定)
InputStream in = or.getOutputSearchDataCsv(rId, DownloadFile.FileType.csv);
DataInputStream dataInStream = new DataInputStream(in);
DataOutputStream dataOutStream = new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream(DOWNLOAD_FOLDER_PATH + DOWNLOAD_CSV_FILENAME)));
// Read Data
byte[] b = new byte[4096];
int readByte = 0;
while (-1 != (readByte = dataInStream.read(b))) {
dataOutStream.write(b, 0, readByte);
}
// Close Stream
dataInStream.close();
dataOutStream.close();
System.out.println("CSVファイルをダウンロードし、以下フォルダーへ保存しました。");
System.out.println(DOWNLOAD_FOLDER_PATH + DOWNLOAD_CSV_FILENAME);
}
とてもシンプルな実装で理解しやすいのではないでしょうか。
実装は以上になります。
本記事でご説明したサンプルソースを以下よりダウンロードいただけます。
※ダウンロードボタンをクリックするとzip形式でダウンロードいただけます。解凍してご確認ください。
※ソースファイルの文字コードはUTF-8です。
※実行の際は必ず「Connect for Java APIを使ってみる1 invoiceAgent Connect for Java APIとは」でご説明したライブラリへクラスパスを通してください。
事項すると以下のようにコンソール出力されます。
1.ログイン成功
2.フォルダー配下にある全ファイルの文書IDを取得
文書ID = 101
文書ID = 100
受付ID = 101
10秒待機します。1回目
10秒待機します。2回目
4.CSVファイル生成完了
CSVファイルをダウンロードし、以下フォルダーへ保存しました。
C:\invoiceAgent_sample\donload\SVFFieldData.csv
5.CSVダウンロード完了
9.ログアウト 成功
SVF検索フィールドの出力リクエストがちょっとクセがありましたが、他の処理についてはわりとシンプルに実装できるとがお分かりいただけたかと思います。
またフォルダー直下のファイルに対して出力リクエストを行いましたが、前回記事の検索と組み合わせてみるとより実用的なシーンがありそうですね。
※本記事の情報は、2023年04月21日現在のものです。(invoiceAgent V10.8.1 / invoiceAgent Cloud Ver.10.8.1.1302)
Related article
Pick up
Ranking
Info