Search
Search


これまでの「invoiceAgentのWeb APIを使ってみる2~3」ではファイルの保存/アーカイブ処理についてご説明しました。
他のシステムとの連携を前提にすると、ファイルをアーカイブした後でそのファイルのプレビュー画面へアクセスさせたい、後で検索させたい、連携したファイルの情報を残しておきたいといったニーズもあるのではないでしょうか。
【APIを利用したプレビュー処理の連携イメージ】
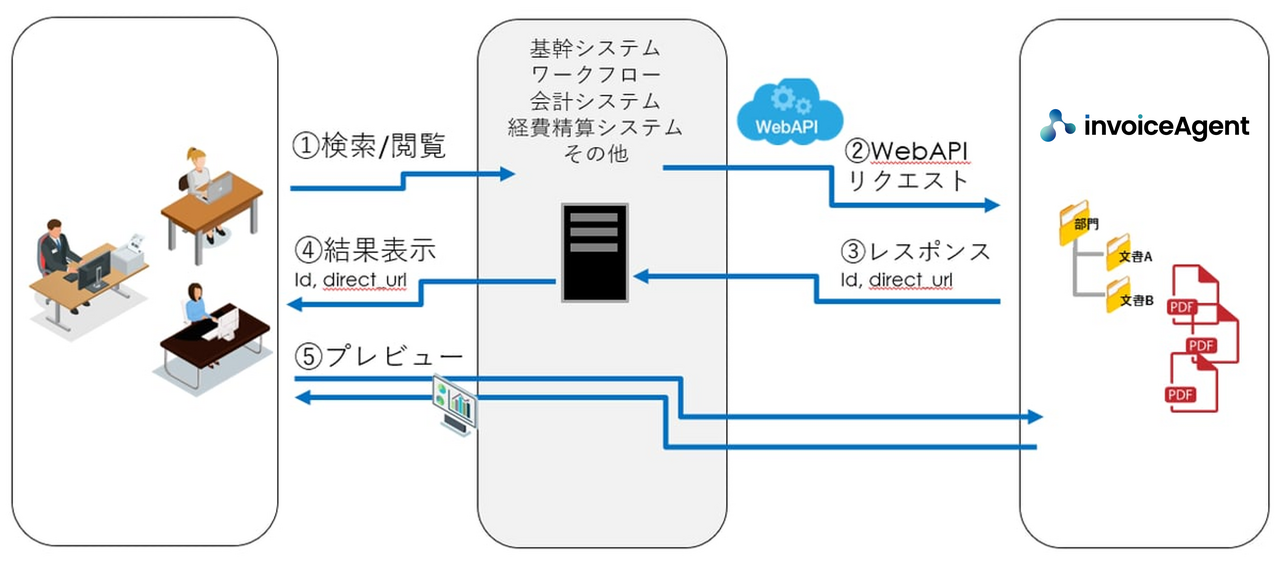
今回はそのような場合に利用できるアーカイブ後に取得できるレスポンスの内容と値の取得方法についてご説明いたします。
言語はJavaを前提にしておりますが、他の言語でも仕組みや考え方は同じです。
以下の解説を一通り実装したサンプルを本記事の末尾のリンクよりダウンロードいただけます。
今回も Archives Add(Ver. 3)というAPIの利用しますが、リクエストの内容についてはこれまでの記事でご説明したので、今回はレスポンスについてご説明します。
※今回はクラウド/オンプレどちらでも利用できるVer. 3の利用としましたが、機能強化に伴い新たなバージョンのAPIが追加されることがあります。実装時には最新バージョンのAPIを確認してください。
詳細は以下マニュアルでご確認ください。
https://cs.wingarc.com/manual/ia/cloud/ja/1426841.html
レスポンスですが以下のようなJSON形式のレスポンスが返ってきます。
{
"id": "10",
"pageCount": 5,
"propertyEntityVersion": 1,
"documentEntityVersion": 1,
"direct_url": "http://<hostname>:44230/spa/preview.jsp?docId=<文書ID>"
}
内容として以下の通りです
| キー名 | データ方 | 内容 |
| id | 文字列 | アーカイブした文書のIDです。 |
| pageCount | 数値 | アーカイブした文書のページ数です。 |
| propertyEntityVersion | 数値 | プロパティのエンティティバージョンです。 |
| documentEntityVersion | 数値 | 文書のエンティティバージョンです。 |
| direct_url | 文字列 | アーカイブした文書のURLリンクです。 |
レスポンスがJSON形式のため今回はJSONライブラリとして有名なJacksonというライブラリを利用します。
※JacksonのバージョンはV2.12.4を前提にしています。
※Jackson自体の利用方法については本記事では説明しませんが、有名なライブラリなので検索等していただければ利用方法の情報は直ぐに見つけることができるかと思います。
今回は「invoiceAgentのWeb APIを使ってみる3 カスタムプロパティをセットしたファイルの保存/アーカイブ」のソースコードに追記する形で作成します。
ファイルを保管/アーカイブした後の処理へ以下の内容を追記してください。
以下のようにレスポンスのInputStreamからJsonNodeを生成し、id,direct_urlを取得します。
System.out.println("アーカイブ成功");
//アーカイブ処理 END ---------------------------------------------------------------------------------------
//アーカイブ後のレスポンス処理 JSONの値取得 START-----------------------------------------------------------
InputStream in = conn.getInputStream();
// 正常終了した場合はJSONを取得できる
ObjectMapper mapper = new ObjectMapper();
JsonNode document = mapper.readTree(conn.getInputStream());
//id
String id = document.get("id").asText();
//direct_url
String direct_url = document.get("direct_url").asText();
System.out.println("id: " + id);
System.out.println("direct_url: " + direct_url);
※ObjectMapper、JsonNode クラスはJacksonライブラリが提供するクラスです。
mainメソッドを呼び出して、実行してみます。
コンソールにはこんな感じの内容が表示されます。
ログイン成功
アーカイブ処理開始
送信完了
アーカイブ成功
id: 75367
direct_url: https://XXXXXXX.spa-cloud.com/spa/preview.jsp?docId=75367
ログアウト成功
Webブラウザを起動し、direct_urlの値へアクセスすると保存したPDFのプレビュー画面へアクセスできることがご確認いただけます。
idは連携元のシステムにこの値を保存しておくことで、検索やファイルのダウンロードといったWeb APIを利用する際にキー値としてご利用いただくことができます。
今回はアーカイブ処理のレスポンスから、ファイルのidやdirect_urlを取得してみました。
基幹システムやワークフロー、Webアプリケーションに添付されたファイルをinvoiceAgentへ登録し、idやdirect_urlをそれらの連携元システムで保存しておくと、連携元システムからinvoiceAgentへ保存したファイルを検索したり、invoiceAgentへアクセスする導線を作ったりといったことができるようになります。
また技術面でも今回のレスポンス処理は、どのAPIでも同じように利用できるので覚えておくと利用できる機会が多いかと思います。
今回ご説明した一連の処理を実行できるサンプルのソースファイルを以下のリンクからダウンロードいただけますので参考にしてみてくださいね。
※ダウンロードボタンをクリックするとzip形式でダウンロードいただけます。解凍してご確認ください。
※ソースファイルの文字コードはUTF-8です。
※オンプレ版invoiceAgentで利用する場合はXSRF-TOKENの処理はコメントアウトしてご利用ください。
※本記事の情報は、2022年01月18日現在のものです。(SPA V10.6.1 / SPA Cloud Ver.10.6.1.1017)
Related article
Pick up
Ranking
Info